MyBatis Dynamic SQL
개요
MyBatis XML 방식의 한계와 대안 모색
기존에 JPA와 QueryDSL을 사용해 SQL을 처리하던 방식과 달리, 회사 정책에 따라 MyBatis만 사용할 수 있는 상황에 직면하게 되었습니다. 그러나 MyBatis의 XML 기반 방식은 가독성과 유지보수성의 문제, 타입 안전성 부족, 동적 SQL의 복잡성 등 여러 단점을 안고 있습니다. 이에 따라 이러한 한계를 극복하고 MyBatis를 더 효율적으로 사용할 수 있는 방법을 고민하게 되었습니다.
MyBatis XML 작성 방식의 대안 라이브러리 탐색
MyBatis XML 방식의 단점을 해결할 두 가지 대안 라이브러리를 찾아보았습니다.
mybatis-ddd
mybatis-dynamic-sql
최종 라이브러리 선택 : mybatis-dynamic-sql
처음에는mybatis-ddd방식을 검토하며 JPA의 메소드 이름 기반 쿼리 자동 생성 기능을 도입해보기도 했습니다. 하지만 이를 완벽하게 구현하기 위해서는 시간이 많이 소요되었으며, 제공되는 메소드의 한정성으로 인해 모든 SQL 처리를 자동화하는 데 한계가 있었습니다.결국, 더 많은 기능을 지원하고 공식 문서가 제공되는
mybatis-dynamic-sql을 채택하였고, 이를 통해 XML 작성 방식을 완전히 대체할 수 있었습니다. 이 라이브러리를 도입한 결과, 코드가 더 간결하고 직관적으로 바뀌었으며, 비즈니스 로직에 더 집중할 수 있게 되었고 유지보수성도 크게 개선되었습니다.
1. ORM 과 MyBatis
MyBatis XML 방식의 불편함
기존에 JPA와 QueryDSL을 사용하던 방식에서 회사 정책상 MyBatis만 허용됨
MyBatis의 XML 방식은 개발시 여러 단점이 존재
단점을 개선해서 MyBatis를 사용할 수 있는 방법에 대해 고민해 봄
Mybatis를 JPA와 QueryDSL과 유사하게 사용하는 방식에 대해 서칭해 봄
1-1. ORM과 Mybatis 차이
(1) ORM (Object-Relational Mapping)
- 객체 지향 프로그래밍 언어에서 관계형 데이터베이스를 다루는 기술
- 객체와 관계형 데이터베이스의 테이블 간의 매핑을 자동으로 처리하는 도구
- SQL 쿼리를 직접 작성하지 않아도 코드 기반으로 DB와 상호작용할 수 있게 해줌
- 자바 객체를 관계형 데이터 베이스에 저장하는데 사용됨
- ORM 프레임워크들(예: Hibernate, JPA)
(2) MyBatis
- 자바 기반의 SQL 매퍼 프레임워크
- SQL을 직접 작성하면서 객체와 데이터베이스 간의 매핑만을 제공함
- ORM이 자동으로 SQL을 생성해 주는 것과 달리, MyBatis는 개발자가 명시적으로 SQL 쿼리 작성하고 이를 자바 객체와 연결하는 방식
- Mybatis 장점
- SQL 직접 제어 : SQL을 세밀하게 제어 할 수 있으며, 성능 최적화가 필요한 경우 유용함
- 복잡한 쿼리 처리 용이 : 복잡한 SQL 쿼리를 직접 작성할 수 있음
1-2. MyBatis XML 방식
- MyBatis 역할
- SQL 쿼리의 결과를 자바 객체로 매핑하거나, 자바 객체를 SQL 쿼리의 입력으로 사용할 수 있게 해줌
- 개발자는 SQL 결과를 도메인 객체로 쉽게 변환하여 비즈니스 로직에서 사용할 수 있음
- MyBatis의 전통적인 방식은 XML 파일에 SQL 문을 작성하고, 이를
Mapper로 사용해 SQL을 관리함
(1) XML 방식 단점
- 유지보수 어려움
- SQL을 XML 파일 내에 작성하기 때문에, 쿼리 로직과 비즈니스 로직 코드가 분리되어 서로의 관계를 파악하기 어려움
- SQL이 복잡해질수록 XML 파일이 커지며, 변경사항이 발생할 때마다 여러 파일을 수정해야 함
- 쿼리 수정시 매핑이나 파라미터 설정 오류가 발생하기 쉬워짐
- 타입 안전성 부족
- XML에서 작성된 SQL문은 컴파일 타임에 오류를 확인할 수 없고, 런타임 시점에만 확인 가능함
- 즉, SQL문에서 발생하는 오류를 사전에 방지하기 어려움
- 동적 SQL의 복잡성 및 가독성 저하
- XML 방식으로 복잡한 동적 쿼리를 작성할 때,
<if>,<choose>등의 태그를 사용해 쿼리 로직을 제어해야함 - 태그 방식은 동적 쿼리 작성의 복잡성을 증가시키고, 가독성이 떨어짐
- XML 방식으로 복잡한 동적 쿼리를 작성할 때,
(2) QueryDSL 방식과 XML 작성 방식 차이
XML 작성 방식 예시
<select id="searchNoticesByCondition" resultType="NoticeResponseDto">
SELECT notice_id, channel, title, secret_type, created_at
FROM notice
<where>
<!-- 날짜 필터 -->
<if test="searchStartDate != null and searchEndDate != null">
AND created_at BETWEEN #{searchStartDate} AND #{searchEndDate}
</if>
<!-- 키워드 필터 -->
<if test="searchKeywordType != null and searchKeyword != null">
<choose>
<when test="searchKeywordType == 'TITLE'">
AND title LIKE CONCAT('%', #{searchKeyword}, '%')
</when>
<when test="searchKeywordType == 'CONTENT'">
AND content LIKE CONCAT('%', #{searchKeyword}, '%')
</when>
<when test="searchKeywordType == 'TOTAL'">
AND (title LIKE CONCAT('%', #{searchKeyword}, '%') OR content LIKE CONCAT('%', #{searchKeyword}, '%'))
</when>
</choose>
</if>
<!-- 채널 필터 -->
<if test="channel != null">
AND channel = #{channel}
</if>
<!-- 비밀 타입 필터 -->
<if test="secretType != null">
AND secret_type = #{secretType}
</if>
</where>
ORDER BY created_at DESC
LIMIT #{pageable.pageSize} OFFSET #{pageable.offset}
</select>
<select id="countNoticesByCondition" resultType="Long">
SELECT COUNT(*)
FROM notice
<where>
<!-- 동일한 조건문을 여기에 반복 -->
<if test="searchStartDate != null and searchEndDate != null">
AND created_at BETWEEN #{searchStartDate} AND #{searchEndDate}
</if>
<if test="searchKeywordType != null and searchKeyword != null">
<choose>
<when test="searchKeywordType == 'TITLE'">
AND title LIKE CONCAT('%', #{searchKeyword}, '%')
</when>
<when test="searchKeywordType == 'CONTENT'">
AND content LIKE CONCAT('%', #{searchKeyword}, '%')
</when>
<when test="searchKeywordType == 'TOTAL'">
AND (title LIKE CONCAT('%', #{searchKeyword}, '%') OR content LIKE CONCAT('%', #{searchKeyword}, '%'))
</when>
</choose>
</if>
<if test="channel != null">
AND channel = #{channel}
</if>
<if test="secretType != null">
AND secret_type = #{secretType}
</if>
</where>
</select>
QueryDSL 작성 방식 예시
public class NoticeRepositoryImpl implements NoticeRepositoryCustom {
private final JPAQueryFactory queryFactory;
// JPAQueryFactory 초기화
public NoticeRepositoryImpl(EntityManager em) {
this.queryFactory = new JPAQueryFactory(em);
}
@Override
public Page<NoticeResponseDto> searchNoticesByCondition(NoticeSearchCondition condition, Pageable pageable) {
// 공지사항 조건에 맞는 리스트 조회
List<NoticeResponseDto> content = queryFactory.select(
new QNoticeResponseDto(notice.noticeId, notice.channel, notice.title, notice.secretType,
notice.createdAt))
.from(notice)
.where(getPredicatesOfCondition(condition)) // 조건에 따른 필터링
.orderBy(notice.createdAt.desc()) // 최신순 정렬
.offset(pageable.getOffset()) // 페이징 처리
.limit(pageable.getPageSize())
.fetch();
// 공지사항 개수 조회 쿼리
JPAQuery<Long> countQuery = queryFactory.select(notice.count())
.from(notice)
.where(getPredicatesOfCondition(condition));
// 페이징된 결과 반환
return PageableExecutionUtils.getPage(content, pageable, countQuery::fetchOne);
}
// 조건에 따른 Predicate 배열 생성
private Predicate[] getPredicatesOfCondition(NoticeSearchCondition condition) {
return new Predicate[] {
createdAtBetween(condition.getSearchStartDate(), condition.getSearchEndDate()), // 날짜 필터
keywordByLike(condition.getSearchKeywordType(), condition.getSearchKeyword()), // 키워드 필터
channelEq(condition.getChannel()), // 채널 필터
secretTypeEq(condition.getSecretType()) // 비밀 타입 필터
};
}
// 날짜 필터
private BooleanExpression createdAtBetween(LocalDate searchStartDate, LocalDate searchEndDate) {
if (searchStartDate == null || searchEndDate == null) {
return null;
}
LocalDateTime searchStartDateTime = searchStartDate.atStartOfDay();
LocalDateTime searchEndDateTime = LocalDateTime.of(searchEndDate, LocalTime.MAX).withNano(0);
return notice.createdAt.between(searchStartDateTime, searchEndDateTime);
}
// 키워드 필터
private BooleanExpression keywordByLike(SearchKeywordType searchKeywordType, String searchKeyword) {
if (searchKeywordType == null || searchKeyword == null) {
return null;
}
String keyword = convertLikeKeyword(searchKeyword);
switch (searchKeywordType) {
case TITLE:
return notice.title.like(keyword);
case CONTENT:
return notice.content.like(keyword);
case TOTAL:
return notice.content.like(keyword).or(notice.title.like(keyword));
default:
return null;
}
}
// 검색어 형식 변환
private String convertLikeKeyword(String searchKeyword) {
return "%" + searchKeyword + "%";
}
// 채널 필터
private BooleanExpression channelEq(Channel channel) {
return channel != null ? notice.channel.eq(channel) : null;
}
// 비밀 타입 필터
private BooleanExpression secretTypeEq(SecretType secretType) {
return secretType != null ? notice.secretType.eq(secretType) : null;
}
}
해결 방안 : MyBatis XML 방식의 단점을 해결할 라이브러리 2가지 모색
mybatis-ddd
mybatis-dynamic-sql
라이브러리 도입으로 인하여 얻은 이점
2. Mybatis-ddd 도입과 확장
2-1. Mybatis-ddd 소개 및 장점
(1) 동작 방식 개요
- mybatis-ddd는 어노테이션 기반의 매핑 방식을 사용함 (ORM에서 엔티티 매핑 방식과 비슷함)
- SQL 쿼리를 XML 파일에 정의하는 대신, Java 인터페이스 메서드에 어노테이션 사용하여 정의함
- SQL 쿼리문을 직접 작성하는 대신,
CrudMapper나PagingAndSortingMapper와 같은 추상화된 매퍼를 사용해 데이터를 처리함
(2) MyBatis-ddd 사용으로 인하여 받은 효과
- 엔티티 클래스에 어노테이션을 추가하고, 기본적인 CrudMapper 인터페이스를 상속받으면 기본적인 SQL 문은 자동으로 생성되므로, SQL 작성에 드는 시간을 절약할 수 있음
- MyBatis XML 방식보다 코드의 간결함을 유지하면서도 높은 생산성을 제공함
- 코드 기반 SQL 관리가 가능하여 XML 파일과의 강한 의존성을 제거할 수 있게 되었고, 유지보수가 더 쉬워짐
- 페이징, 조건 기반 조회 등을 위한 매퍼 인터페이스를 재사용하여 중복 코드를 줄이고, 개발 효율성 높여줌
2-2. Mybatis-ddd 사용 방식과 구조
(1) 사용 예시
- 엔티티에 작성한
@Id,@Column,@Table등의 어노테이션에 따라 Mapper가 동작함 CrudMapper와SqlProvider를 통해 SQL이 자동으로 생성됨
@Getter
@Table(name = "teacher", schema = "BI_DEV")
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Teacher {
@Id
@Column(name = "id", insertable = false, updatable = false)
private Long id;
@Column(name = "name")
private String name;
@Column(name = "school_id")
private Long schoolId;
// 생략
}
public interface TeacherMapper extends CrudMapper<Teacher, Long>, PagingAndSortingMapper<Teacher, Long>, QueryByCriteriaMapper<Teacher, Long> {
}(2) 주요 Mapper 인터페이스
- CrudMapper
- 기본적인 CRUD (Create, Read, Update, Delete) 작업을 처리하는데 사용됨
- 엔티티를 저장, 조회, 수정, 삭제 할 때 SQL이 자동 생성 됨
**CrudMapper 인터페이스 로직**
public interface CrudMapper<T, ID extends Serializable> {
데이터 삽입을 위한 SQL을 제공
@InsertProvider(type = CrudSqlProvider.class)
int save(T entity);
@SelectProvider(type = CrudSqlProvider.class)
Optional<T> findById(ID id);
@SelectProvider(type = CrudSqlProvider.class)
List<T> findAllById(@Param("ids") Iterable<ID> ids);
@SelectProvider(type = CrudSqlProvider.class)
long count();
@DeleteProvider(type = CrudSqlProvider.class)
int deleteById(ID id);
@DeleteProvider(type = CrudSqlProvider.class)
int delete(T entity);
@DeleteProvider(type = CrudSqlProvider.class)
int deleteAllById(@Param("ids") Iterable<ID> ids);
@InsertProvider(type = CrudSqlProvider.class)
int create(T entity);
@UpdateProvider(type = CrudSqlProvider.class)
int update(T entity);
@UpdateProvider(type = CrudSqlProvider.class)
int dynamicUpdate(T entity);
@InsertProvider(type = CrudSqlProvider.class)
int createAll(@Param("entities") Iterable<T> entities);
}
- PagingAndSortingMapper
- 페이징 및 정렬 기능을 제공하는 Mapper
- 페이징 처리를 간단하게 처리할 수 있게 됨
PagingAndSortingMapper 인터페이스 로직
public interface PagingAndSortingMapper<T, ID extends Serializable> {
@SelectProvider(type = PagingAndSortingSqlProvider.class)
List<T> findAll(Pageable pageable);
}- QueryByCriteriaMapper
- 다양한 검색 조건을 기반으로 데이터를 조회하는 Mapper
- 조건에 따른 조회, 복잡한 쿼리 로직을 직관적으로 처리할 수 있게 됨
QueryByCriteriaMapper 인터페이스 로직
public interface QueryByCriteriaMapper<T, ID extends Serializable> {
@SelectProvider(type = QueryByCriteriaProvider.class)
Optional<T> findOne(Criteria<?> criteria);
@SelectProvider(type = QueryByCriteriaProvider.class)
List<T> findBy(Criteria<?> criteria);
@SelectProvider(type = QueryByCriteriaProvider.class)
long countBy(Criteria<?> criteria);
}
(3) SqlProvider 클래스 역할
- SqlProvider 클래스는 주어진 조건에 따라 동적 SQL 쿼리를 동적으로 생성하는 클래스
**CrudSqlProvider 클래스 로직**
public class CrudSqlProvider<T, ID extends Serializable> extends SqlProviderSupport<T, ID> {
// 생략
public String create(T domin, ProviderContext ctx) {
String sql = new SQL()
.INSERT_INTO(this.tableName(ctx))
.INTO_COLUMNS(this.insertIntoColumns(ctx))
.INTO_VALUES(this.intoValues(ctx))
.toString();
return sql;
}
public String findById(ProviderContext ctx) {
String sql = new SQL()
.SELECT(this.selectColumns(ctx))
.FROM(this.tableName(ctx))
.WHERE(this.wheresById(ctx))
.toString();
if(log.isTraceEnabled()) { log.trace("created sql : " + sql); }
return sql;
}
}PagingAndSortingSqlProvider 클래스 로직
public class PagingAndSortingSqlProvider<T, ID extends Serializable> extends SqlProviderSupport<T, ID> {
public String findAll(Pageable pageable, ProviderContext ctx) {
String sql = new SQL()
.SELECT(selectColumns(ctx))
.FROM(tableName(ctx))
.ORDER_BY(orders(pageable.getSort(), ctx))
.OFFSET_ROWS("#{offset}")
.FETCH_FIRST_ROWS_ONLY("#{limit}")
.toString();
return sql;
}
}QueryByCriteriaProvider 클래스 로직
public class QueryByCriteriaProvider<T, ID extends Serializable> extends SqlProviderSupport<T, ID> {
// 생략
public String findBy(Criteria<?> criteria, ProviderContext ctx) {
SQL sql = new SQL()
.SELECT(selectColumns(ctx))
.FROM(tableName(ctx))
.WHERE(wheresByCriteria(criteria, ctx));
if (criteria.getPageable() != null) {
sql.OFFSET_ROWS("#{pageable.offset}");
sql.FETCH_FIRST_ROWS_ONLY("#{pageable.limit}");
Sort sort = criteria.getPageable().getSort();
if (sort != null) { sql.ORDER_BY(orders(sort, ctx)); }
} else if (criteria.getSort() != null) {
sql.ORDER_BY(orders(criteria.getSort(), ctx));
}
return sql.toString();
}
}
2-3. Mybatis-ddd 한계
(1) Mybatis-ddd의 사용시 문제점
기본 제공되는 Mapper 인터페이스 부실
Mybatis-ddd에서 제공하는 어노테이션 기반 매핑 방식은 매우 편리하였음
엔티티에 어노테이션만 작성하고, CrudMapper를 상속받은 매퍼 인터페이스만 생성하면 자동으로 SQL문을 작성해 주기 때문에 개발 생산성을 대폭 상승 시켜주었음
하지만, 제공되는 메소드가 한정적이였기 때문에 모든 쿼리문을 자동 생성해주지 않음
예를 들어 findById는 제공하지만 findByFieldA, findByFieldB 와 같이 다양한 필드를 기준으로 조회하는 메소드는 제공되지 않음
(2) JPA 동작 방식 탐구
아이디어 도출
제공되는 메소드가 한정적인 문제를 해결하기 위해 Spring Data JPA의 동작 방식을 참고함
JPA는 메소드 이름을 기반으로 쿼리를 자동으로 생성하는 기능을 제공
Mybatis-ddd에서 제공하는 라이브러리 코드를 직접 가져와서 업그레이드 해보기로 함
메소드 네이밍 기반 자동 쿼리 생성 기능을 구현하여 적용
- JPA(Java Persistence API) 에서
findByName과 같이 메소드 이름에 따라 쿼리를 자동 생성하는 기능은 Spring Data JPA에서 제공됨 - Spring Data JPA를 사용하면 SQL 쿼리를 직접 작성하지 않고도 간편하게 DB를 다룰 수 있음
Spring Data JPA 란?
- Spring 프레임워크의 일부로서, JPA를 사용하여 DB와 상호 작용하는데 도움을 주는 기능을 제공함
- Spring Data JPA에서는 Repository 인터페이스를 정의하고, 이를 확장하는 인터페이스를 만들어 사용함
- 메소드 이름에 따라 쿼리를 자동 생성할 수 있도록 지원함
- 이를 통해 개발자는 직접 SQL 쿼리를 작성하지 않고도 DB에서 데이터를 가져오거나 조작할 수 있음
JPA Repository간 상속 계층 구조
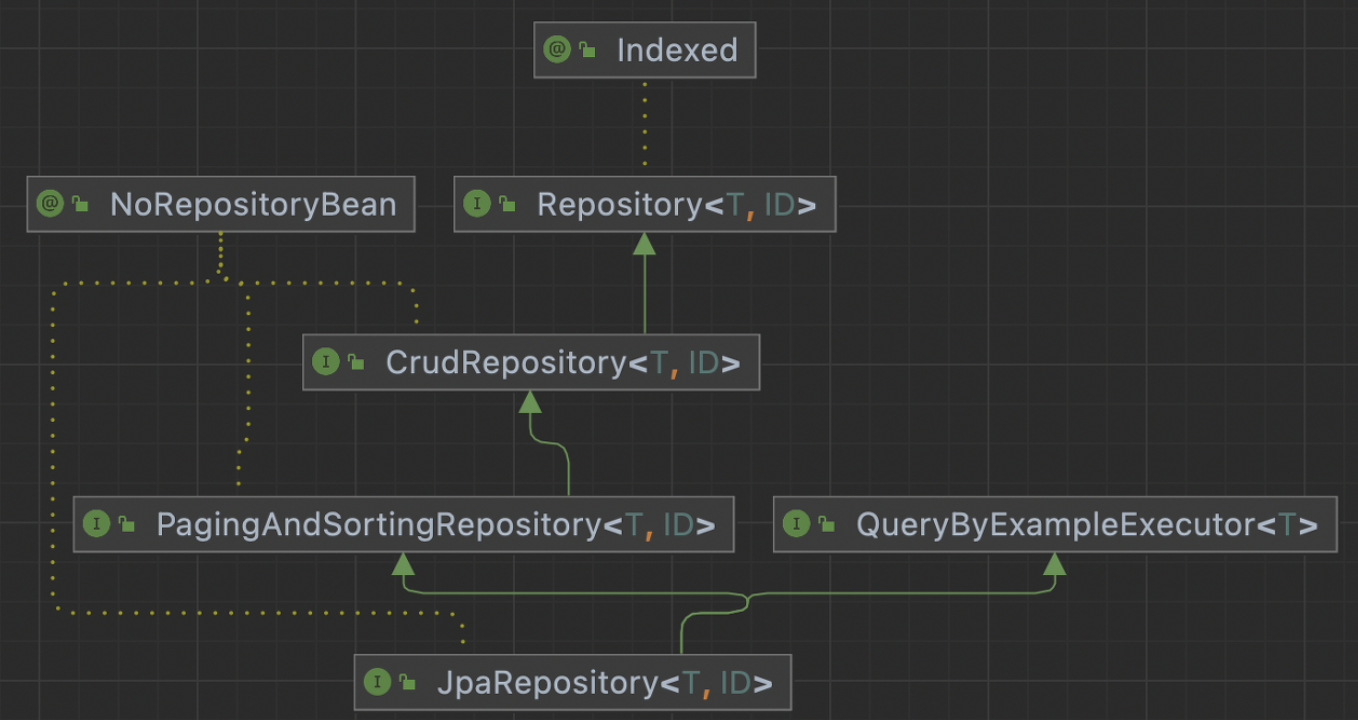
-
CrudRepository와 JpaRepository 둘다
Repository를 확장한 인터페이스 임 -
CrudRepository
-
Spring Data JPA의 기본 인터페이스
-
Repository를 상속받으며 CRUD 기능이 명세되어있음
@NoRepositoryBean public interface JpaRepository<T, ID> extends PagingAndSortingRepository<T, ID>, QueryByExampleExecutor<T> { List<T> findAll(); T getById(ID id); // 생략 }
-
-
JpaRepository
-
CrudRepository를 상속한PagingAndSortingRepository를 상속받음 -
CrudRepository를 확장하여 JPA 특정 기능을 추가로 제공함
-
기본적인 CRUD 기능과 더불어 페이징 및 정렬 관련 기능 명세도 추가되어있음
@NoRepositoryBean public interface CrudRepository<T, ID> extends Repository<T, ID> { <S extends T> S save(S entity); Optional<T> findById(ID id); void deleteById(ID id); // 생략 }
-
Spring Data JPA 핵심 : SimpleJpaRepository
- SimpleJpaRepository 클래스는 Spring Data JPA에서 제공하는 기본 구현체
CrudRepository의 모든 기능을 구현하고 있음- JpaRepository와 CrudRepository 인터페이스를 구현하여 JpaRepository에서 정의된 JPA 관련 메소드들을 사용할 수 있도록 함
- 이 클래스는 DB와의 상호 작용을 수행하고, 쿼리를 실행하여 엔티티를 생성, 조회, 수정, 삭제할 수 있도록 도와줌
- JPARepository 사용 예시
UserRepository는JpaRepository를 확장하여User엔티티를 다루는데 사용됨- 메소드 이름에 따라 Spring Data JPA는 적절한 쿼리를 생성함
findByName과findByAge메소드를 정의했기 때문에 이 메소드들을 호출할 때 Spring Data JPA는 각각name과age필드에 따라 데이터를 조회하는 쿼리를 생성
public interface UserRepository extends JpaRepository<User, Long> {
// 메소드 이름으로 쿼리 생성
List<User> findByName(String name);
List<User> findByAge(int age);
}findByName 동작 원리
@Override public Optional<T> findOne(@Nullable Specification<T> spec) {
try {
return Optional.ofNullable(getQuery(spec, Sort.unsorted()).getSingleResult());
} catch (NoResultException | NonUniqueResultException ex) {
return Optional.empty();
}
}- Spring Data JPA의 메소드 네이밍 규칙을 따라 정의된 메소드는 실제로
SimpleJpaRepository클래스에서 어떤 메소드를 호출하는가?findByName()은SimpleJpaRepository에서 QueryCreationListener를 통해 Query 메소드로 변환됨. 이는 메소드 이름에 따라 적절한 JPQL 또는 SQL 쿼리를 생성하여 데이터베이스에서 데이터를 조회하는 것을 의미함- 구체적으로
findByName메소드는SimpleJpaRepository클래스에서 findOne() 메소드 호출로 이어짐 findOne메소드는 JPA Criteria API를 사용하여Specification을 생성하고, 해당Specification을 기반으로 JPQL 쿼리를 생성하고 실행하여 결과를 반환함
2-4. 메소드 네이밍 기반 자동 쿼리 생성 기능 구현
(1) 특정 필드 기준 조회 메소드 구현
- findByName(), findByAge() 등 필요한 필드 기준으로 조회할 수 있도록 메소드를 각각 구현
- 구현 로직
public interface CrudMapper<T, ID extends Serializable> {
@SelectProvider(type = CrudSqlProvider.class)
Optional<T> findByName(String name);
}public class CrudSqlProvider<T, ID extends Serializable> extends SqlProviderSupport<T, ID> {
public String findByName(ProviderContext ctx) {
String sql = new SQL()
.SELECT(this.selectColumns(ctx))
.FROM(this.tableName(ctx))
.WHERE(this.wheresByName(ctx))
.toString();
return sql;
}
}(2) 특정 필드 기준 조회 메소드 구현 방식 한계
- 처음에는
findByName,findByAge와 같이 각 필드마다 별도의 메소드를 구현하는 방식으로 접근함 - 하지만 모든 필드마다 메소드를 수동으로 작성하는 것은 매우 번거로웠고, 필드명이 변경될 경우에도 해당 메소드를 일일이 수정해야 하는 비효율적인 작업이 필요했음
- 이러한 문제를 해결하기 위해 JPA처럼 메소드 이름에서 필드명을 추출하여 자동으로 쿼리를 생성하는 방식을 적용하면 좋겠다는 아이디어가 떠올랐음
- Mybatis-ddd 라이브러리를 수정하여, 메소드 네이밍 규칙을 활용해 필드명을 자동으로 추출하고, 해당 필드 기준으로 동적으로 SQL 쿼리를 생성하는 기능을 구현함
(3) 메소드명 기반으로 동작하도록 구현
- 자동 쿼리 생성 기능 설명
- 메소드 이름을 분석해 findByXxx와 같은 메소드에서 Xxx 부분을 필드명으로 추출하여, 해당 필드에 맞는 조회 쿼리를 자동으로 생성함
- findByTitle()와 같이 findByXxx 같은 경우 findByAttribute()가 동작하도록 구현
- findByAttribute()는 By를 기준으로 split하여 해당 필드 기준으로 검색함
- ex. findByTitle인 경우 필드에 title이 있다면 title 기준
- 단일 필드 기준으로만 동작하며, 중복된 필드로 조회할 경우 에러가 발생하도록 설계함 (유일성 보장)
- 로직 예시 및 설명
- 메소드 컨텍스트: ctx.getMapperMethod()를 사용하여 실행 중인 메소드를 가져옴
- 속성 추출: “findBy” 접두사를 제거하여 속성 이름을 추출함
- 컬럼 변환: convertAttributeToColumn 메소드를 사용하여 CamelCase를 snake_case로 변환함
- SQL 쿼리 생성 및 반환 : SQL 클래스를 사용하여 동적으로 쿼리를 생성하고, 쿼리를 문자열로 반환함
public interface TeacherMapper {
@SelectProvider(type = CrudSqlProvider.class, method = "findByAttribute")
Optional<Teacher> findByName(@Param("value") Object value);
@SelectProvider(type = CrudSqlProvider.class, method = "findByAttribute")
Optional<Teacher> findByAge(@Param("value") Object value);
}public interface CrudMapper<T, ID extends Serializable> {
@SelectProvider(type = CrudSqlProvider.class)
Optional<T> findByAttribute(@Param("value") Object value);
}public class CrudSqlProvider<T, ID extends Serializable> extends SqlProviderSupport<T, ID> {
public String findByAttribute(ProviderContext ctx) {
Method method = ctx.getMapperMethod();
String methodName = method.getName();
String attribute = methodName.substring(methodName.indexOf("By") + 2);
String column = convertAttributeToColumn(attribute);
return new SQL()
.SELECT(this.selectColumns(ctx))
.FROM(this.tableName(ctx)) // 실제 테이블 이름
.WHERE(this.wheresByAttribute(ctx, column)) //.WHERE(column + " = #{value}")
.toString();
}
// attribute를 SQL 쿼리에 적절한 형태로 변환 - CamelCase를 snake_case로 변환
private String convertAttributeToColumn(String attribute) {
return attribute.replaceAll("([a-z])([A-Z])", "$1_$2").toLowerCase();
}
}3. Mybatis Dynamic SQL
3-1. Mybatis-ddd 대신 채택 이유
mybatis-ddd 대신 mybatis-dynamic-sql 방식을 채택한 이유
처음에는 mybatis-ddd 라이브러리를 사용해보았으나, 몇가지 한계에 직면함
mybatis-dynamic-sql 방식만의 장점
3-2. MyBatis Dynamic SQL 소개
(1) MyBatis Dynamic SQL 설명 및 장점
- SQL을 동적으로 생성하고 효율적으로 관리할 수 있는 라이브러리
- QueryDsl과 유사한 형태로 SQL 생성을 도와줌
- 사용시 장점
- Java 코드로 작성: SQL 쿼리를 XML 대신 Java 코드처럼 작성 가능, 코드 내에서 SQL 작성 및 실행
- 코드 재사용성: SQL 구문을 Java 코드로 표현하여 재사용성과 유지보수성 향상
- 동적 SQL 작성 간소화: 복잡한 동적 SQL 작성을 단순화하고, 더 직관적인 SQL 작성이 가능해짐
- 타입 안정성: 컴파일 시점에 SQL 구문을 확인해 런타임 오류 감소
- 비즈니스 로직 집중: SQL 작성의 부담을 줄여 개발자가 비즈니스 로직에 집중할 수 있게 도움
(2) MyBatis Dynamic SQL의 핵심 구성 요소
- DynamicSqlSupport 클래스
- SQL 구문 생성을 위한 다양한 메서드를 제공하는 클래스
select,from,where,orderBy등의 메서드를 사용하여 SELECT, FROM, WHERE, ORDER BY 구문을 자동으로 생성할 수 있음 → SQL 작성의 간편함과 가독성을 높여줌
- Mapper 인터페이스
- MyBatis와 데이터베이스 간의 상호 작용을 정의하는 부분
- Mapper 인터페이스에 정의된 메서드는 SQL 쿼리를 실행하는 데 사용되며, MyBatis가 데이터베이스와 상호 작용하는 방식을 정의하고 있음
- Mapper인터페이스의 메서드를 호출하여 SQL 쿼리를 실행하고, 결과를 반환함
(3) MyBatis Dynamic SQL 라이브러리 적용
- 동적 쿼리 생성을 위해 MyBatis Dynamic SQL 사용하기 위해서는 의존성 추가
implementation 'org.mybatis.dynamic-sql:mybatis-dynamic-sql:+
- Mybatis-dynamic-sql 참고 페이지
3-3. MyBatis Dynamic SQL 적용 예시 코드
MyBatis Dynamic SQL을 활용하여 Player 테이블에 대한 동적 SQL을 작성하는 예시
(1) Player 엔티티
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Player {
private Long id;
private String firstName;
private String lastName;
private Boolean employed;
private Team team; // 객체 매핑 가능해짐
@Builder
public Player(String firstName, String lastName, Boolean employed, Team team) {
this.firstName = firstName;
this.lastName = lastName;
this.employed = employed;
this.team = team;
}
}(2) PlayerDynamicSqlSupport 클래스
public final class PlayerDynamicSqlSupport {
public static final Player player = new Player();
public static final SqlColumn<Long> id = player.id;
public static final SqlColumn<String> firstName = player.firstName;
public static final SqlColumn<String> lastName = player.lastName;
public static final SqlColumn<Boolean> employed = player.employed;
public static final SqlColumn<Long> teamId = player.teamId;
public static final class Player extends SqlTable {
public final SqlColumn<Long> id = column("id", JDBCType.BIGINT);
public final SqlColumn<String> firstName = column("first_name", JDBCType.VARCHAR);
public final SqlColumn<String> lastName = column("last_name", JDBCType.VARCHAR/*, "com.tmax.krcc.domain.example.handler.LastNameTypeHandler"*/);
public final SqlColumn<Boolean> employed = column("employed", JDBCType.VARCHAR, "com.tmax.krcc.common.handler.BooleanCharTypeHandler");
public final SqlColumn<Long> teamId = column("team_id", JDBCType.BIGINT);
public Player() {
super("Player");
}
}
}(3) PlayerMapper 인터페이스
public interface PlayerMapper extends CommonCountMapper, CommonDeleteMapper, CommonInsertMapper<Player>, CommonUpdateMapper {
@SelectProvider(type = SqlProviderAdapter.class, method = "select")
@Results(id = "PlayerResult", value = {
@Result(column = "player_id", property = "id", jdbcType = JdbcType.BIGINT, id = true),
@Result(column = "first_name", property = "firstName", jdbcType = JdbcType.VARCHAR),
@Result(column = "last_name", property = "lastName", jdbcType = JdbcType.VARCHAR),
@Result(column = "employed", property = "employed", jdbcType = JdbcType.CHAR, typeHandler = BooleanCharTypeHandler.class),
@Result(column = "team_id", property = "team.id", jdbcType = JdbcType.BIGINT),
@Result(column = "uuid", property = "team.uuid", jdbcType = JdbcType.VARCHAR),
@Result(column = "name", property = "team.name", jdbcType = JdbcType.VARCHAR),
@Result(column = "description", property = "team.description", jdbcType = JdbcType.VARCHAR),
@Result(column = "team_type", property = "team.teamType", jdbcType = JdbcType.INTEGER,
typeHandler = EnumOrdinalTypeHandler.class)
})
List<Player> selectMany(SelectStatementProvider selectStatement);
@SelectProvider(type = SqlProviderAdapter.class, method = "select")
@ResultMap("PlayerResult")
Optional<Player> selectOne(SelectStatementProvider selectStatement);
BasicColumn[] selectList =
BasicColumn.columnList(id.as("player_id"), firstName, lastName, employed,
team.id.as("team_id"), team.uuid, team.name, team.description, team.teamType);
default int insert(Player player) {
return MyBatis3Utils.insert(this::insert, player, PlayerDynamicSqlSupport.player,
c -> c.map(firstName).toProperty("firstName")
.map(lastName).toProperty("lastName")
.map(employed).toProperty("employed")
.map(teamId).toProperty("team.id"));
}
default List<Player> select(SelectDSLCompleter completer) {
QueryExpressionDSL<SelectModel> start =
SqlBuilder.select(selectList)
.from(player)
.join(team, on(teamId, equalTo(team.id)));
return MyBatis3Utils.selectList(this::selectMany, start, completer);
}
default Optional<Player> selectOne(SelectDSLCompleter completer) {
QueryExpressionDSL<SelectModel> start = SqlBuilder.select(selectList).from(player)
.join(team, on(teamId, equalTo(team.id)));
return MyBatis3Utils.selectOne(this::selectOne, start, completer);
}
default Optional<Player> selectById(Long id_) {
return selectOne(c ->
c.where(id, isEqualTo(id_))
);
}
}