ASM 모듈 인메모리 캐시 도입
ASM 모듈의 역할과 기존 구조 문제점
1. ASM 모듈이란?
- ASM(Agent State Manager) 모듈은 상담원의 상태를 관리하는 핵심 컴포넌트
- 상담원 상태 관리: 로그인/로그아웃, READY(상담 가능), NOT_READY(휴식/이석) 등 관리
- 상태 변경 이벤트 처리: 상태 변경 이벤트를 수신하고 처리하여 다른 시스템에 기준 데이터 제공
- 기준 데이터 제공: 상담 가능 여부 판단, 상담 배분(Routing) 엔진이 상담원을 선정시 최우선 판단 기준
- 상담 시스템에서 상담원의 상태는 모든 로직의 출발점에 해당됨
- ASM 모듈은 타 모듈 및 외부 시스템 연동 진입점 역할을 함
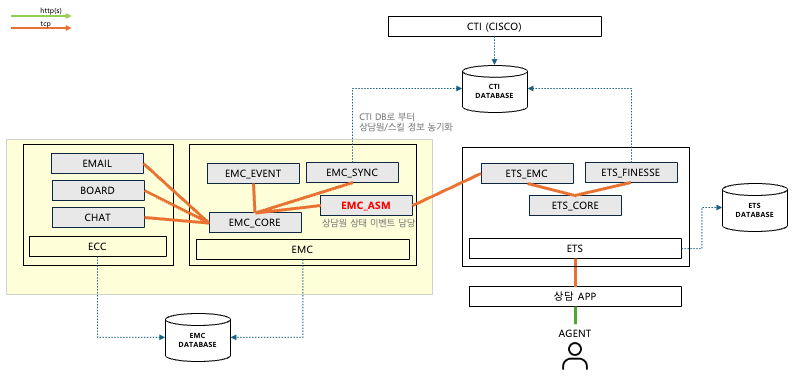
2. 기존 로그인 흐름
- 상담원이 상담 애플리케이션에 접속하면, 채널별로 로그인 상태를 확인함
- 전화 상담 로그인: CTI 시스템을 통해 전화 상담 가능 여부 확인
- 멀티미디어 상담 로그인: ASM 모듈을 통해 멀티미디어 상담 가능 여부 확인
- 아래 구조에서 멀티미디어 상담의 정상 동작 여부는 ASM 모듈의 상태와 응답에 강하게 의존하고 있음
3. 기존 구조의 문제점
- (1) DB 중심의 강함 결합 구조
- 기존 시스템은 모든 상태 변경이 발생할 때마다 DB에 직접 Write하고, 상담 인입 시마다 DB를 Read하여 상태를 확인하는 구조
- 상담원 상태 변경시 → 즉시 DB 반영
- 상담 가능 여부 판단 → DB 조회를 통해 상태 확인
- 상담 배분 모듈 → 상담원 선정을 위해 DB 조회 수행
- ASM 모듈 정상 여부 판단 → DB 헬스체크 결과에 의존
- 즉, 상담원의 상태의 변경, 조회, 모듈 정상 여부 판단이 모두 DB 연결 상태에 강하게 결합된 구조
- 기존 시스템은 모든 상태 변경이 발생할 때마다 DB에 직접 Write하고, 상담 인입 시마다 DB를 Read하여 상태를 확인하는 구조
- (2) DB 장애가 곧 서비스 장애로 확산
- 이 구조에서 부분 장애를 전체 장애로 확대시키는 단일 장애 지점(SPOF)이 존재하게 됨
- DB 연결이 불안정해지는 순간 발생하는 문제
- 연쇄 장애: DB 네트워크에 미세한 순단만 발생해도 ASM 모듈의 헬스체크가 실패
- 서비스 마비: ASM이 비정상이 되면 상담원 앱은 강제 로그아웃 처리되며, DB가 복구될 때까지 상담사는 로그인을 할 수 없는 ‘전면 업무 중단’ 상태에 빠짐
- 확장성 저하: 상담 인입이 몰릴수록 상태 조회 쿼리가 급증하여 DB 부하를 가중시킴
개선 전략: 캐시를 통한 장애 격리
DB 장애 상황에서도 상담원이 최소한의 상담 업무는 지속할 수 있도록 변경하고자 함
1. 개선 목표
- 부분 장애가 전체 장애로 확대되는 구조적 한계 개선
- DB가 일시적으로 불안정해도 상담원 상태 관리와 상담 배분은 계속 가능해야 함
- DB 장애 상황에서도 시스템이 스스로 버틸 수 있도록 하는 것이 목표
2. 왜 인메모리인가?
- 상담원 상태 데이터는 다음과 같은 특성이 있음
- 전체 상담원 수는 수천 명 단위로, 메모리에 충분히 적재 가능
- 조회(Read) 빈도가 쓰기(Write)보다 압도적으로 높음
- 상담원 상태 변경 시점: 출퇴근시, 휴식/복귀, 일정 시간 상담 수락 불가시 상태 전환 등
- 상담원 인입시 모든 상담원 상태 조회 (콜이 많을 수록 빈도 증가)
- 복잡한 조인이나 검색보다는 Key-Value 형태의 접근이 주를 이룸
- 상담원 상태를 인메모리로 관리시 장점
- 조회 성능 향상
- DB가 장애 상황에서도 상담원 상태 변경 및 조회 유지 가능
캐시 디자인 패턴
1. Cache 목적
- 성능 향상 및 부하 감소
- 캐시는 application과 영속적 데이터저장소 사이에서 임시 저장소 역할
- 일반적인 시스템에서 캐시는 Read 성능을 극대화하는 용도로 사용됨
- 그러나 Write 요청이 많은 시스템에서의 캐시는 쓰기 버퍼 역할을 담당하기도 함
- 쓰기 요청 건마다 개별 처리하는 것이 아니라
- 캐시에 버퍼링된 쓰기 요청을 적당히 모아 한 번에 처리하는 것
- 네트워크 오버헤드를 상당 부분 감소시킬 수 있는 장점 있음
- Write-Behind 패턴 구조
2. Cache Aside 패턴 (Lazy Loading, 지연로딩 패턴)
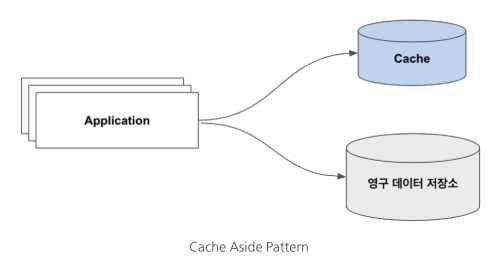
- 가장 많이 사용되는 캐시 패턴
- 해당 데이터를 Application이 필요로 할 때 캐시에 로딩되므로
지연 로딩으로 불림 - 캐시와 영속적 데이터 저장소는 병렬로 구성되며, 애플리케이션은 양쪽 소스에 직접 연결됨
- 애플리케이션이 데이터를 읽어가는 과정은 2-Phase로 동작함
- 우선 원하는 데이터가 캐싱되어 있는지 체크한 후에 값이 있다면 그 값을 반환
- 없다면 데이터 저장소에 가서 원하는 값을 읽어옴
- 가져온 값은 캐시에 저장한 후 애플리케이션에 반환
| 장점 | • 캐시 미스(Cache Miss, 캐시에 데이터가 없다는 뜻)가 치명적이지 않음 ⇒ 데이터 저장소에서 읽어와 적재하면 됨 • 클라이언트가 요청한 데이터에 한해서 캐싱하므로 캐시 히트율이 높음 ◦ 리소스를 효율적으로 사용할 수 있음 ◦ 파레토의 법칙에 따라, 전체 데이터의 20% 리소스로도 80% 정도의 요청을 캐싱할 수 있음 • 구조가 단순하여 기존 코드에 손쉽게 적용할 수 있음 |
|---|---|
| 단점 | • 항상 2단계로 체크해야 하므로 읽기 과정이 복잡해짐 • 캐시 미스가 발생해야 데이터 저장소에서 데이터를 읽어오므로, 캐싱된 데이터가 최신이 아닐 수 있음 • Cold Start 상태에서 성능을 발휘하기 위해서는 Warm-Up 시간이 필요함 ◦ ColdStart 란? 캐싱된 데이터가 없는 상태로 시스템이 시작되는 경우 (↔ Warm Start ) ◦ ColdStart 상황에서 접속이 대량으로 발생할 경우, 여러 곳에서 한꺼번에 데이터 저장소의 원본 데이터를 요청하는 Thundering Herd 문제가 발생함 |
3. Read-Through 패턴 (Inline Cache 패턴)
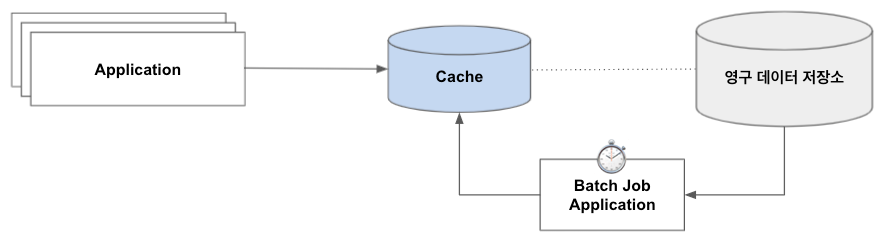
- 캐시는 Application과 DB 사이에 위치하며, Application은 캐시에만 연결됨
- Application과 DB의 연결선 상에 Cache가 위치한다고 하여
인라인 캐시로 불림 - 캐시의 적재 및 갱신은 비동기적으로 이루어짐
- 주기적으로 배치 담당 Application이 데이터 저장소의 데이터를 읽어와 캐시에 적재함
- Read-Through 패턴은 전체 데이터를 캐싱하는 일괄 처리 작업 특성상, 대량 데이터를 캐싱하기는 어려움
- 주로 다음과 같이 한정적 범위를 가지는 데이터를 캐싱하는 데 사용됨
- 국가별 환율 데이터
- 현재 노출 중인 공지 목록
- 어제까지의 누적 방문자 수
- 모바일 앱의 메인 페이지 콘텐츠 데이터
- 주로 다음과 같이 한정적 범위를 가지는 데이터를 캐싱하는 데 사용됨
| 장점 | • 캐시 적재 요청을 단일화할 수 있기 때문에, Cold Start 상황에서도 큰 문제가 발생하지 않음 • Application은 캐시를 최종 데이터 저장소처럼 인식하므로, 데이터를 읽어오는 로직을 단순화할 수 있음 |
|---|---|
| 단점 | • 주기적으로 캐시와 DB 사이를 동기화할 배치 어플리케이션을 만들고 관리해야 함 • 캐시 히트율과 상관없이 모든 데이터를 캐싱하기 때문에, 캐싱된 데이터가 반드시 읽힌다는 보장이 없음 ⇒ 캐시 히트율이 낮아질 수 있음 • DB에 저장되어 있더라도 캐시 공간 부족으로 일부 데이터가 캐싱되지 못하면 Applicaion도 참조 불가 |
3. Write-Through 패턴
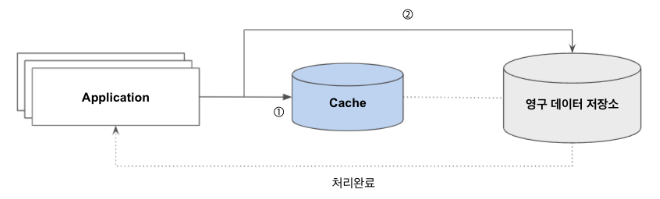
- 캐시는 Application과 DB 사이에 위치하지만, 쓰기 시점에 캐시가 적재됨
- Application은 저장할 데이터를 먼저 캐시에 기록한 후 이어서 데이터 저장소에도 업데이트함
- 해당 과정은 동기적으로 처리되기 때문에 쓰기 속도가 느려짐
- 처리 과정
- 캐시에 데이터를 저장함. 이미 있는 경우에는 업데이트함
- DB에 데이터를 추가하거나 업데이트함
- 처리 결과를 애플리케이션에 응답함
- 동일한 데이터에 대한 읽기는 상대적으로 빠르게 동작함
- 읽을 때가 아니라 쓸 때 캐싱하는 방식이므로 캐싱된 데이터를 최신으로 유지할 수 있음
- 다만 캐시에 쓰여진 대부분의 데이터가 반드시 읽힌다는 보장은 없음 (즉, 캐시 히트율이 낮아질 수 있음)
| 장점 | • 쓰기 처리 시에 캐싱되므로, 캐시를 최신 데이터로 유지할 수 있다. |
|---|---|
| 단점 | • 쓰기 지연이 발생함 • 캐싱된 대부분의 데이터가 반드시 읽힌다는 보장이 없음 ( 즉, 리소스 낭비를 야기함) |
4. Write-Behind 패턴 (Write-Back)
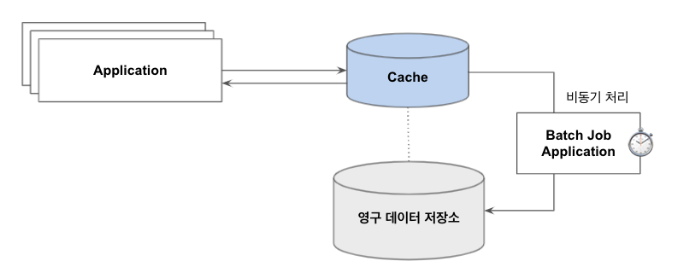
- Write-Through의 쓰기 성능 문제에 대한 대안으로 사용되는 패턴
- 데이터를 먼저 캐시에 기록하고, 결과를 먼저 애플리케이션에 반환함
- 캐시에 저장된 데이터는 이후 별도의 비동기 프로세스를 이용하여 데이터 저장소에 업데이트함
- 즉, 이 패턴에서 캐시는 일종의 쓰기 버퍼 역할을 함
더티 캐시(Dirty Cache)- 캐시에만 저장되고 아직 데이터 저장소에 반영되지 않은 것을 말함 (Dirty Block 이라고도 함)
- Dirty Cache는 비동기 처리 애플리케이션을 통해 데이터 저장소에 동기화하기 때문에 배치 처리를 담당할 별도의 애플리케이션이 필요 함
- Read-Through 패턴과 유하사하지만 배치 처리 프로세스의 흐름 방향이 반대임
- 쓰기 요청을 한 번에 모아서 처리하므로 네트워크 오버헤드를 감소시킬 수 있음
- 쓰기 성능이 향상됨 = 쓰기가 많은 작업에 적합한 패턴
- 예를 들어 로깅이나 이벤트 수집, Compaction 처리가 필요한 이벤트 소싱 데이터 등에 적용하기 좋음
- 처리 과정
- 애플리케이션이 캐시에 데이터를 추가하거나 업데이트함
- 캐시 레벨에서 기록이 끝나면 결과를 반환함
- 이후 캐시에서 비동기적으로 데이터 저장소에 업데이트함
| 장점 | • 네트워크 오버헤드를 감소시켜 쓰기 성능을 향상시킬 수 있음 |
|---|---|
| 단점 | • 다른 캐시 전략에 비해 구현이 어렵다. • 캐시에 업데이트된 후 아직 데이터 저장소에 업데이트 되기 전 더티 캐시 가 다운되면 데이터 손실이 발생함 |
해결 방안 1: Write-Behind 패턴과 Redis 사용
- 캐시 디자인 패턴 중 가능한 대안
- DB 장애 상황에서도 ASM 모듈이 정상 동작하기 위해서는 캐시에 우선적으로 데이터를 저장해야 함
Write-Through 패턴과Write-Behind 패턴사용 가능- 두 패턴의 차이는 영구 데이터 저장소에 반영 시점 차이
- Write-Behind 패턴과 Redis 사용 고려
- Write-Behind 패턴
- 캐시에 먼저 쓰고 DB에 비동기 반영하므로 DB 의존도를 가장 최소화
- DB 장애 발생 후 정상화시, 영구저장소에 적재되지 않은 데이터를 비동기적으로 적재할 수 있음
- Redis 사용
- 여러 서버에서 상담원 상태를 일관되기 관리 가능
- 서버 재시작/배포 시에도 상태 유실 위험 감소
- TTL 활용하여 운영 종료시 자동 로그아웃 처리도 용이함
- Write-Behind 패턴
현실적 제약: Redis 사용 불가
인프라 운영 부담: 고객사 인프라 정책상 미들웨어(Redis) 설치 불가한 경우 존재
운영 포인트 증가 및 비용 이슈
팀 내부 논의 결과
해결 방안 2: Write-Through 패턴 사용
- Redis 없이 로컬 Map에서 관리시 발생하는 문제
- Redis를 사용시 모든 모듈이 DB에 의존하지 않고, 인메모리 캐시를 바라보도록 변경할 예정이었음
- Redis 사용 대신 ASM 모듈 내부에서 Map으로 상담원 상태 관리 방식 사용 결정
- 현재 구조상 발생하는 문제
- 타 모듈들은 ASM 이벤트를 통해서 동작하지 않고, DB의 상담원 상태 관련 테이블을 기준으로 동작
- ASM 내부 캐시와 DB 상태가 어긋나면 실시간 일관성 붕괴 발생
- 로컬 Map에만 저장하면 DB를 바라보는 다른 모듈들과의 정합성을 어떻게 맞출 수 있을 것인가?
- 다른 모듈에서는 ASM 모듈의 로컬 Map의 실시간 최신 데이터를 접근 불가
- Write-Through 기반의 이중 구조를 설계 고려
- 설계의 핵심
- ASM 모듈 내부의
ConcurrentHashMap이 항상 최신 상태를 유지하는 기준 데이터가 됨 - 쓰기 시점에 AMS 모듈 내부 인메모리(Map)와 영구 데이터 저장소에 모두 저장하는 방식 사용 → 동시에 저장하므로 일관성 붕괴 최소화
- 모든 상태 조회는 DB를 거치지 않고 메모리에서 즉시 반환 → 조회 성능 향상
- ASM 모듈 내부의
왜 ConcurrentHashMap 사용?
단일 JVM 환경에서 멀티스레드 접근에 대한 안정성과 고성능을 동시에 확보하기 위함
HashMap은 Thread-Safe하지 않음
Hashtable이나SynchronizedMap은 맵 전체에 락이 걸기 때문에 성능 저하가 큼
→ 한 스레드가 작업 중이면 다른 모든 스레드가 대기해야 하는 병목 현상 발생
ConcurrentHashMap
- 장애 복구 시나리오 (Self-Healing)
- DB 장애 시에도 상담 업무를 지속하기 위한 세부 로직을 구축
- DB 장애 중:
- 상태 변경/조회는 메모리에서 정상 처리 (상담 업무 유지)
- 히스토리 로그는 유실 방지를 위해 내부 인메모리 Queue에 임시 적재
- DB 복구 시:
- 실시간 상태: 메모리 데이터를 기준으로 DB 테이블을 재생성하여 동기화
- 이력 데이터: Queue에 쌓인 데이터를 순차적으로 DB에 Write.
- 현재 구조의 한계와 향후 과제
- 현재 구조는 장애 상황에서도 상담 업무는 계속할 수 있게 한다는 목표를 달성함
- 하지만 이 구조에서도 한계는 있음
- 단일 서버 제약: ASM 모듈 내부 메모리를 사용하므로 다중 서버일 경우, 서버 간 상태 불일치 발생
- 의존성 전이: 현재 상담 배분 로직이 DB Join을 사용하고 있어, 타 모듈의 DB 의존도를 완전히 끊지는 못함
- 차후 계획
- 타 모듈이 DB를 직접 조회하는 대신 ASM 모듈의 이벤트를 수신하거나 API를 호출하도록 변경하여 DB 의존도를 점진적으로 낮출 예정
저장소 의존성 분리
- Repository 인터페이스 도입
- 추후 Redis 도입이나 DB 교체에 유연하게 대응하기 위해 인터페이스로 추상화함
- DB Repository / In-Memory Repository 각각 구현
- 추후 Redis 도입 시에도 구조 변경 최소화
- 설정 기반 저장소 전환
- 설정(configuration) 파일 변경만으로 저장소를 전환할 수 있도록 구성
- 운영 환경에 따라 적절한 저장소 선택 가능
캐시를 바라보는 관점의 변화
과거 캐시 활용
이번 프로젝트를 통한 발견
역할 전환의 의미