SQLD 이론 요약 - part 3. SQL 활용
📗 Part 3. SQL 활용
1. 서브쿼리
- 서브 쿼리 - 위치에 따른 분류 : 스칼라 서브쿼리, 인라인뷰, 중첩 서브쿼리
| 서브 쿼리 종류 | 사용 가능한 위치 | |
|---|---|---|
스칼라 서브쿼리 ( Scalar Subquery) |
SELECT 절 | Colum명 대신 사용 되므로 반드시 하나의 값만 반환해야 함 |
| Inline View (인라인 뷰) |
FROM 절 | 테이블명 대신 사용 가능 |
| 중첩 서브쿼리 (Nested Subquery |
Where 절, Having 절 | main 쿼리와의 관계에 따른 분류 : 연관 / 비연관 반환 데이터 형태에 따른 분류 : 단일행 / 다중행 / 다중 컬럼 |
# 스칼라 서브쿼리 예시 : 각 학생의 최고 성적 반환
SELECT user_id,
(SELECT MAX(score) FROM test t
WHERE t.user_id = test.user_id) AS highest_score
FROM test;
# 리뷰 테이블에 없는 제품명 데이터를 출력
SELECT r.product_id
(SELECT p.product_name FROM product p
WHERE p.product_id = r.product_id) AS product_name,
r.review_content
FROM review r;
# 에러 발생 !! 하나의 값만 반환하지 않음
SELECT r.product_id
(SELECT p.product_name, p.price FROM product p
WHERE p.product_id = r.product_id) AS product_info,
r.review_content
FROM review r;
# 인라인 뷰 예시 : 학생마다 평균 성적 계산
SELECT user_id, avg_score
FROM (
SELECT user_id, AVG(score) AS avg_sore FROM test GROUP BY user_id
) avg_scores;- 중첩서브 쿼리 분류
| 중첩 서브쿼리 분류 기준 | 종류 | |
|---|---|---|
| main 쿼리와의 관계 | 연관 서브쿼리 |
서브쿼리 내에 main 쿼리의 컬럼 존재함 |
비연관 서브쿼리 |
서브쿼리가 main 쿼리와 관계 맺고 있지 않음 | |
| 반환 데이터 형태 | 단일 행 서브쿼리 | 서브쿼리가 1건 이하의 데이터 반환 단일행 비교 연산자와 함께 사용 ( < , > , <= , >= ) |
| 다중 행 서브쿼리 | 서브쿼리가 여러 건의 데이터 반환 다중 행 비교 연산자와 함께 사용 ( ex. IN , ALL , ANY , SOME, EXISTS ) |
|
| 다중 컬럼 서브쿼리 | 서브쿼리가 여러 컬럼의 데이터를 반환 |
# 연관 서브쿼리 예시 : 각 학생의 최고 점수 찾기
SELECT student_id, score FROM test t1
WHERE score = (SELECT MAX(score) FROM test t2
WHERE t1.student_id = t2.student_id );
# 비연관 서브쿼리 예시 : 서브쿼리 내에는 메인 쿼리의 컬럼이 존재 하지 않음
SELECT student_id, age, school_code
FROM student
WHERE school_code = (SELECT school_code from school_name = '강남초');# 다중 컬럼 서브쿼리 예시 : 특정 과목에서 최고 점수를 기록한 학생 찾기
# (user_id, score)가 서브쿼리에서 반환된 (user_id, MAX(score))와 일치하는 행만 출력
SELECT user_id, course, score FROM test
WHERE (user_id, score) IN (
SELECT user_id, MAX(score) FROM test GROUP BY user_id
);# IN : main쿼리 데이터가 sub쿼리 결과 중 "하나라도 일치" 하면 true
# 각 부서별 최고 급여와 동일한 급여(salary) 받는 사원(employ) 출력
SELECT * FROM employ
WHERE salary IN ( SELECT MAX(salary) FROM employ GROUP BY department );
# ANY, SOME : main쿼리의 조건식을 만족하는 sub쿼리 결과가 "하나 이상" 이면 true
# 모든 과목에서 최고 성적을 받은 학생 출력
SELECT student_id, name FROM student
WHERE student_id = ANY (SELECT student_id FROM test
WHERE score = (SELECT MAX(score) FROM test));
# ALL : main쿼리의 조건식을 sub쿼리의 결과가 "모두 만족"하면 true
# 모든 과목에서 성적이 70점 이상인 학생 출력
SELECT student_id, name FROM student s
WHERE 70 <= ALL (SELECT score FROM test t WHERE t.student_id = s.student_id);
# EXISTS : sub쿼리 결과가 존재하면 (행이 1개 이상일 경우) true
# 성적이 90점 이상인 과목이 있는 학생 출력
SELECT name FROM student s
WHERE EXISTS ( SELECT 1 FROM test t WHERE t.student_id = s.student_id
AND grade >= 90);| 비교 연산자 | ||
|---|---|---|
| IN | 특정 값이 지정된 목록에 있는 경우 | SELECT * FROM users WHERE age IN(10,20); |
| ANY | 최소한 하나라도 만족하는 것 | ANY는 비교연산자와 함께 사용함 |
=ANY (IN과 동일) |
SELECT * FROM users WHERE age = any(10,20);나이가 10, 20 중 하나라도 만족하는 사용자 |
|
>ANY (최소값 보다 크면) |
SELECT * FROM users WHERE age > any(10,20);age > 10 OR age > 20 과 동일 = 나이가 10보다 큰 경우 |
|
<ANY (최댓값 보다 작으면) |
SELECT * FROM users WHERE age < any(10,20);age < 10 OR age < 20 과 동일 = 나이가 20보다 작은 경우 |
|
!ANY (NOT IN과 동일) |
||
| ALL | 모두 만족하는 것 | ALL은 비교연산자와 함께 사용함 |
=ALL |
SUBSELECT 결과가 1건이면 상관없지만 여러 건이면 오류 발생 | |
>ALL : 최대값 보다 크면 |
SELECT * FROM users WHERE age > all(10,20);age > 10 AND age > 20 과 동일 = 나이가 20보다 큰 경우 |
|
<ALL : 최솟값 보다 작으면 |
SELECT * FROM users WHERE age < all(10,20);age < 10 AND age < 20 과 동일 = 나이가 10보다 작은 경우 |
|
!ALL |
SUBSELECT의 결과가 여러 건이면 오류가 발생 |
💡 서브쿼리 설명
- 서브쿼리는 ORDER BY 절, INSERT문의 VALUE절 등에 사용 가능
- 다중 행 서브쿼리의 경우 ‘=’ 조건과 함께 사용 불가
- 다중 컬럼 서브쿼리의 경우 IN절과 함께 사용 가능
2. View (뷰)
- View
- 특정 SELECT문에 이름을 붙여 재사용 가능하도록 저장해놓은 오브젝트
- 뷰는 가상테이블이므로, 실제 데이터를 저장하지 않고 해당 데이터를 조회해오는 SELECT문만 갖고 있음
- View의 특징
보안성: 보안이 필요한 컬럼 가진 테이블인 경우, 별도의 View를 생성해 제공독립성: 테이블 스키마 변경되었을 경우, Application 변경하지 않고, 관련 View만 수정 가능편리성: 복잡한 쿼리 구문을 View명으로 대체 사용 가능 → 가독성이 높아짐- 사용자는 내부적으로 View 생성 SQL을 볼 수 없음 (투명하지 않음)
# 뷰 생성
CREATE OR REPLACE VIEW DEPT_MEMBER AS
SELECT d.dept_id, d.dept_name, m.member_name, m.phone
FROM department d LEFT OUTER JOIN member m ON d.dept_id = m.dept_id
# 뷰 사용 : 생성한 view이름 사용
SELECT * FROM DEPT_MEMBER WHERE dept_name = 'IT'; # IT 부서 인원 조회
SELECT dept_name, COUNT(*) FROM DEPT_MEMBER GROUP BY dept_id; # 부서별 인원수 조회3. 집합 연산자
| 집합 연산자 | 각 쿼리의 결과 집합을 가지고 연산하는 명령어 |
|---|---|
| UNION ALL | 중복 허용 + 합집합 (각 쿼리 결과의 합집합) |
| UNION | 중복 없음 + 합집합 (중복된 행은 한줄만 출력됨) |
| INTERSECT | 중복 없음 + 교집합 select * from A INTERSECT select * from B |
| MINUS / EXCEPT | 중복 없음 + 차집합 = 앞의 쿼리 결과에서 뒤의 쿼리 결과를 뺀 |
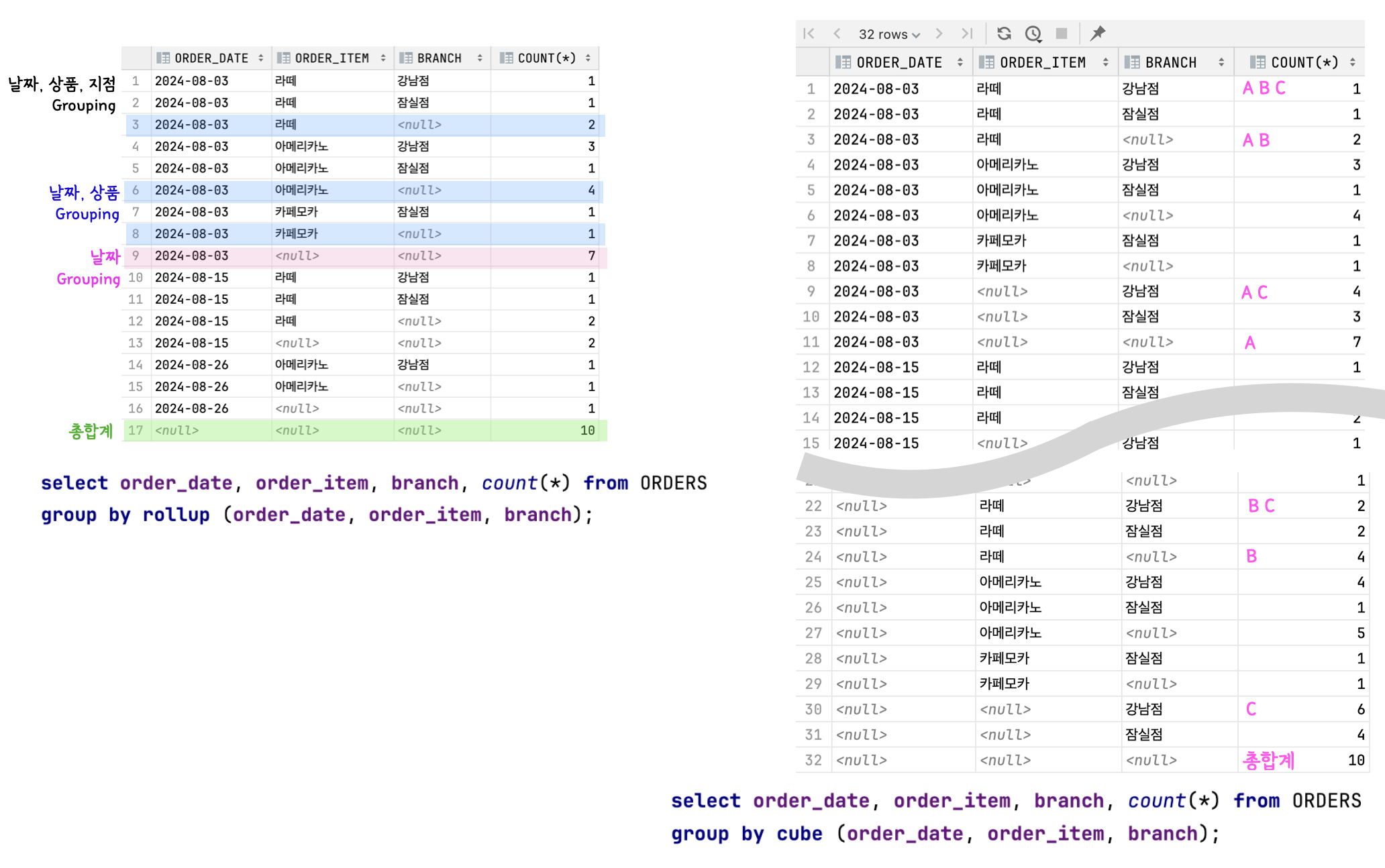
4. 그룹 함수
- 그룹함수
- GROUP BY하여 나타낼 수 있는 데이터를 구하는 함수
- 그룹함수 분류 - 역할에 따라
- 소계(총계) 함수 →
ROLLUP,CUBE,GROUPING SETS - 집계 함수 →
COUNT,SUM,AVG,MIN
- 소계(총계) 함수 →
(1) 소계(총계) 함수 = 소 그룹 간의 소계 및 총계 계산하는 함수
| ROLLUP | ROLLUP은 인수의 순서에 따라 결과가 달라짐 ↔ CUBE 와 GROUPING SET은 인수 순서와 상관 없음 |
|---|---|
| ROLLUP( A, B, C ) | A, B, C로 그룹핑 + A, B 로 그룹핑 + A로 그룹핑 + 총합계 |
| ROLLUP( (A, B), C ) | A,B, C 로 그룹핑 + A,B 로 그룹핑 + 총합계 |
| ROLLUP( A, (B, C) ) | A, B,C 로 그룹핑 + A 로 그룹핑 + 총합계 |
| CUBE | 조합할 수 있는 모든 그룹에 대한 소계를 집계 |
|---|---|
| CUBE ( A, B, C ) | A, B, C 그룹핑 + A, B 그룹핑 + A, C 그룹핑 + B , C 그룹핑 + A그룹핑 + B 그룹핑 + C 그룹핑 + 총합계 |
| CUBE( (A, B), C ) | A,B, C 그룹핑 + A,B 그룹핑 + C 그룹핑 + 총합계 |
| CUBE ( A, (B, C) ) | A, B,C 로 그룹핑 + A 로 그룹핑 + B,C 그룹핑 + 총합계 |
| GROUPING SETS | 특정 항목에 대한 소계 계산 |
|---|---|
| GROUPING SETS ( A, B ) | A 그룹핑 + B 그룹핑 |
| GROUPING SETS ( A, B , ( ) ) | A 그룹핑 + B 그룹핑 + 총합계 |
| GROUPING SETS ( A, ROLLUP (B , C) ) | ROLLUP(B, C)→ B, C 그룹핑 + B그룹핑 + 총합계 이므로결과 : A 그룹핑 + B ,C 그룹핑 + B 그룹핑 + 총합계 |
| GROUPING SETS ( A, B, ROLLUP(C) ) | A 그룹핑 + B 그룹핑 + C 그룹핑 + 총합계 |
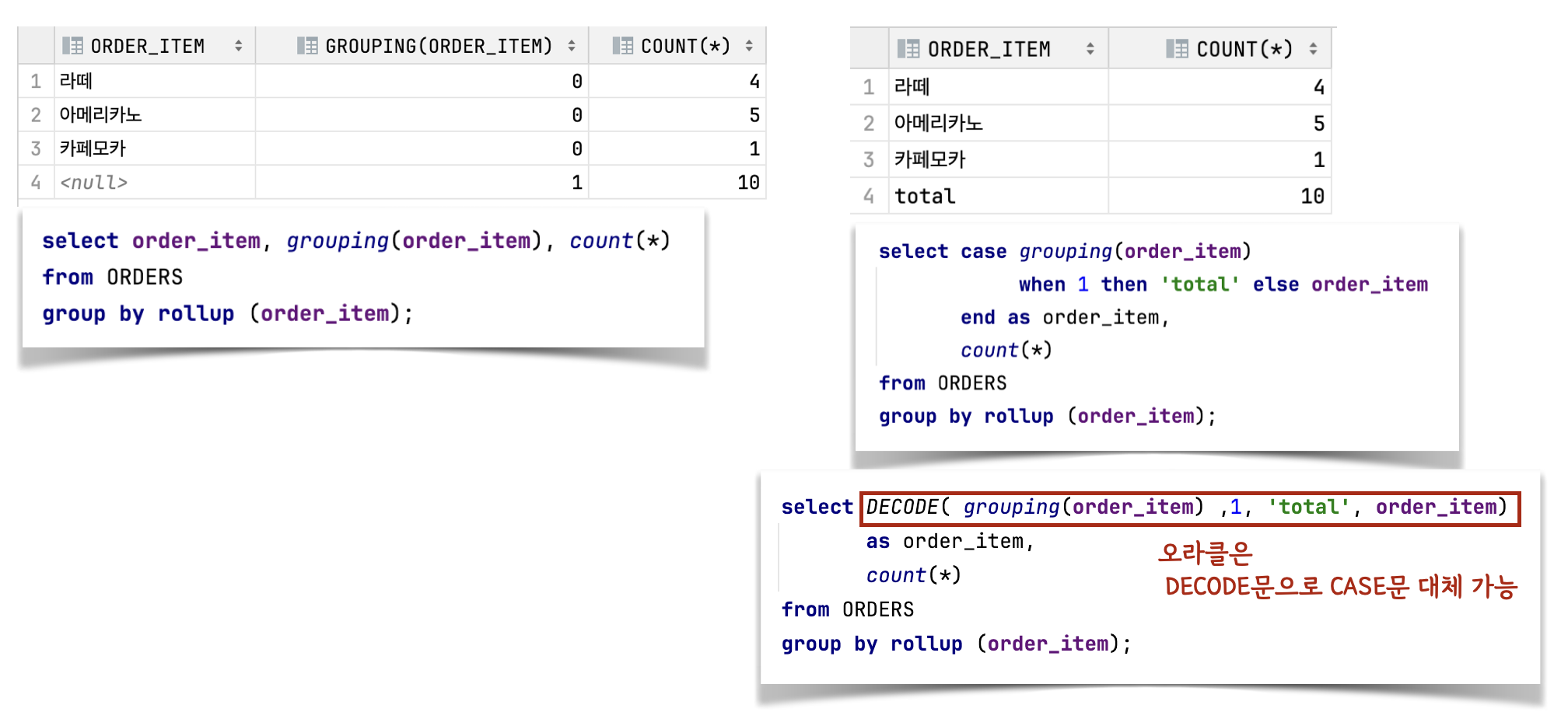
(2) GROUPING
- ROLLUP, CUBE, GROUPING SETS와 함께 사용됨
- 소계 ROW에서 그룹핑 기준 컬럼 이외에 NULL 값이 들어가는데, 원하는 텍스트로 변경시 활용
- GROUPING 함수의 결과값이 1이 되고, 나머지 ROW에서는 이 됨
4. 윈도우 함수
- 윈도우 함수 → OVER 키워드와 함게 사용됨
- 윈도우 함수 분류 - 역할에 따라
- 순위 함수 :
RANK,DENSE_RANK,ROW_NUMBER - 집계 함수 :
SUM,MAX,MIN,AVG,COUNT - 행 순서 함수 :
FIRST_VALUE,LAST_VALUE,LAG,LEAD - 비율 함수 :
CUME_DIST,PERCENT_RANK,NTILE,RATIO_TO_PEPORT
- 순위 함수 :
| 순위 함수 | [count] 9 8 7 7 7 6 5 | |
|---|---|---|
| RANK | 같은 순위 존재하는 만큼 다음 순위 건너뜀 | [ 결과 ] 1 2 3 3 3 6 7 |
| DENSE_RANK | 같은 순위 존재하더라도 이어서 순위 매김 ( dense = 밀집한 → 순위가 밀집 ) |
[ 결과 ] 1 2 3 3 3 4 5 |
| ROW_NUMBER | 순서가 동일해도 각기 다른 순서 부여함 | [ 결과 ] 1 2 3 4 5 6 7 |
# 윈도우 함수 : OVER 키워드와 함께 사용됨
# 순위 함수 RANK 예시 : 날짜별로 주문 카운트해서 높은순으로 순위 매김
SELECT order_date, COUNT(*), RANK() OVER (ORDER BY COUNT(*) DESC) AS RANK
FROM orders
GROUP BY order_date
# 순위 함수 ROW_NUMBER 예시 : 부서별 급여 높은 사원부터 순위 매김
SELECT member_name, dept_id, salary,
ROW_NUMBER() OVER (PARTITION BY dept_id ORDER BY salary DESC) AS ROW_NUM
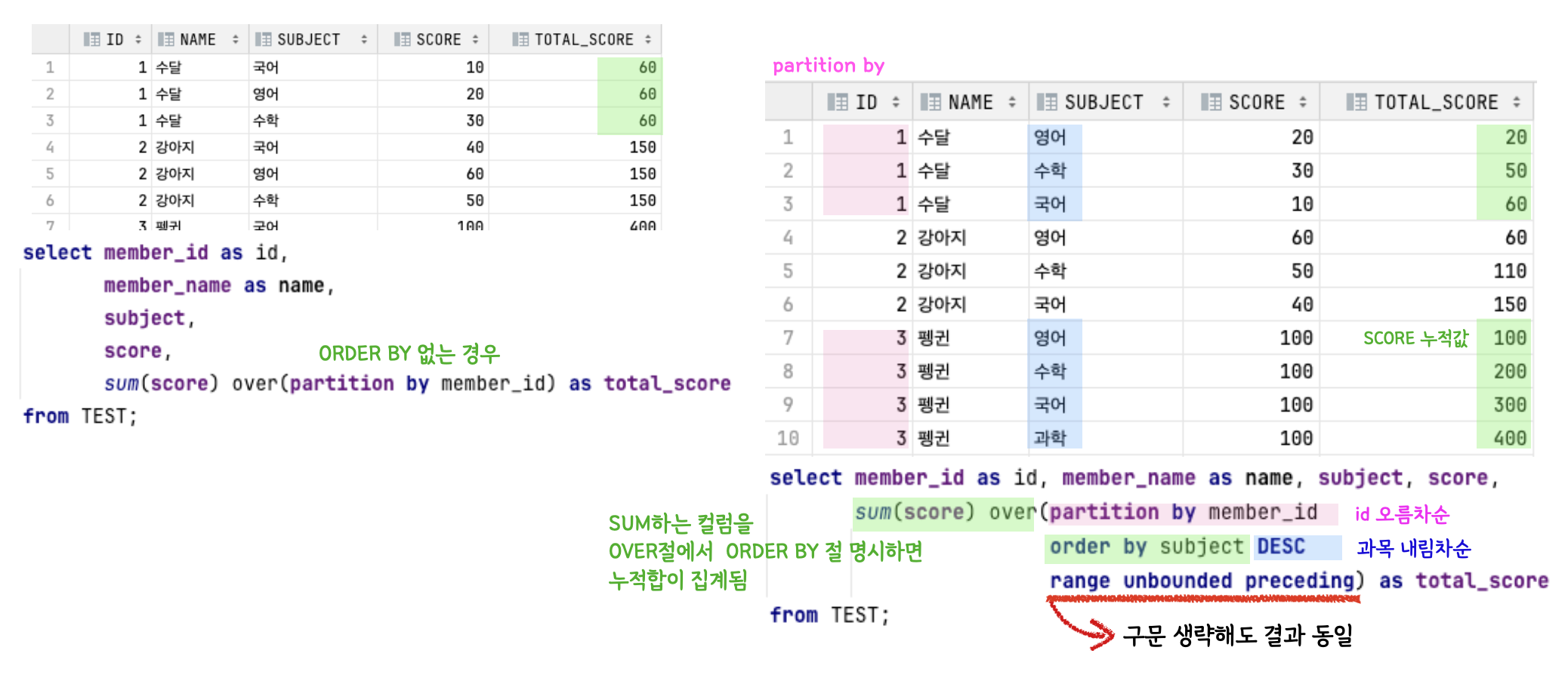
FROM employees;| 집계 함수 | |
|---|---|
| SUM | 데이터 합계 구하는 함수 → 인자값으로 숫자형만 가능 오라클에서는 OVER절 내에 ORDER BY절 사용시 데이터 누적값 구할 수 있음 |
| MAX / MIN | 데이터 최댓값 / 최솟값 구하는 함수MAX(score) OVER(partition by subject) as max_score |
| AVG | 데이터 평균값 구하는 함수ROUND( AVG(score) OVER(partition by subject) ) as avg_score |
| COUNT | 데이터의 건수를 구하는 함수 |
# 윈도우 함수 옵션
RANGE BETWEEN unbounded preceding AND current row # 현재행 ~ 위쪽끝행
RANGE unbounded preceding # 위쪽 끝행 (항상 본인 포함됨)
ROWS BETWEEN current row AND 5 following
ROWS BETWEEN 5 preceding AND unbounded following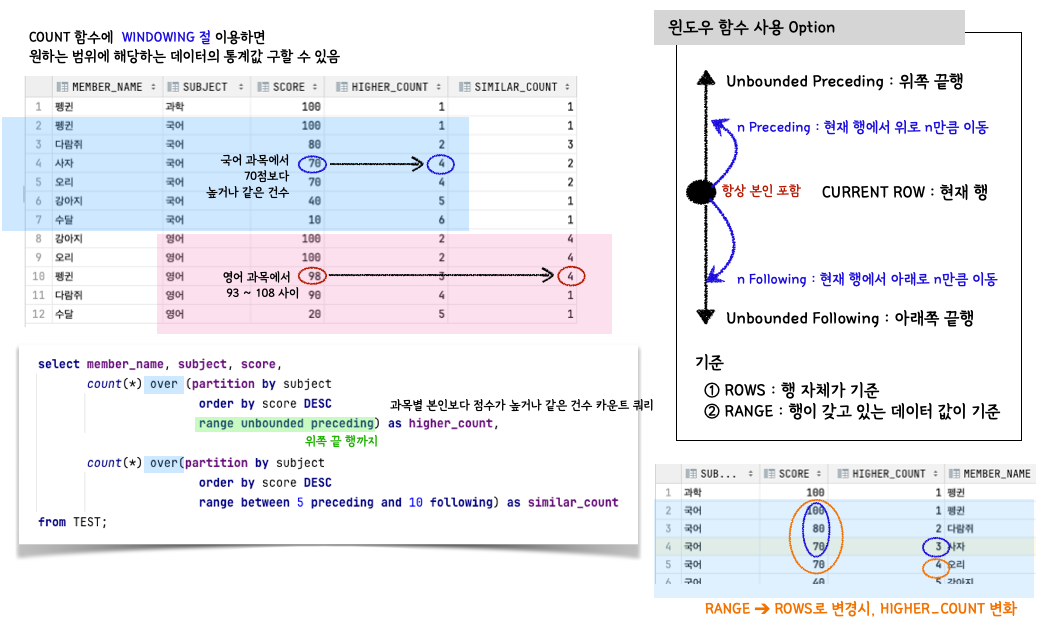
| 행 순서 함수 | ⚠️ MSSQL 지원 안함 |
|---|---|
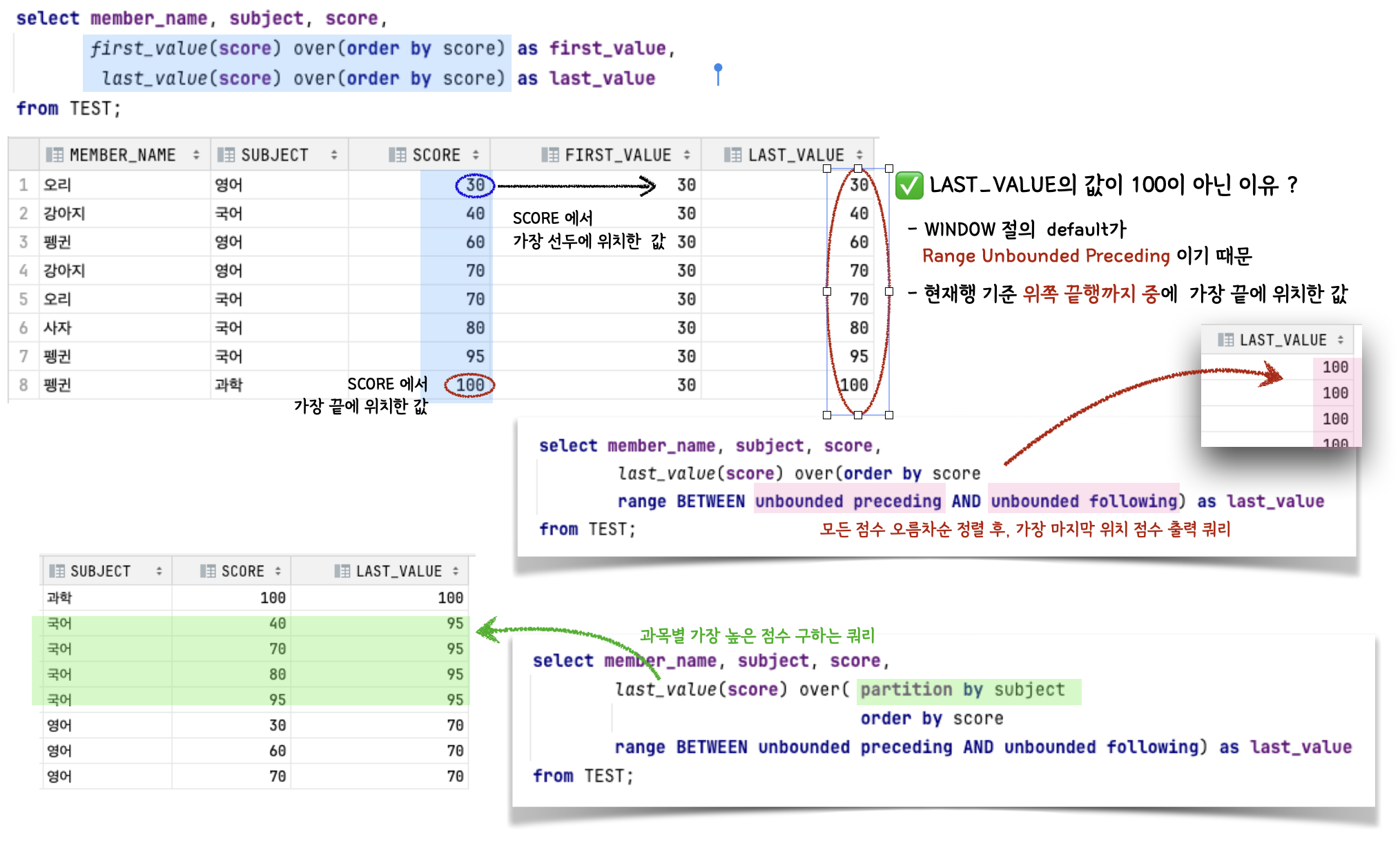
| FIRST_VALUE LAST_VALUE |
파티션별 가장 선두 / 가장 끝에 위치한 데이터 구함✅ WINDOW절 default 옵션이 RANGE UNBOUNDED PRECEDING |
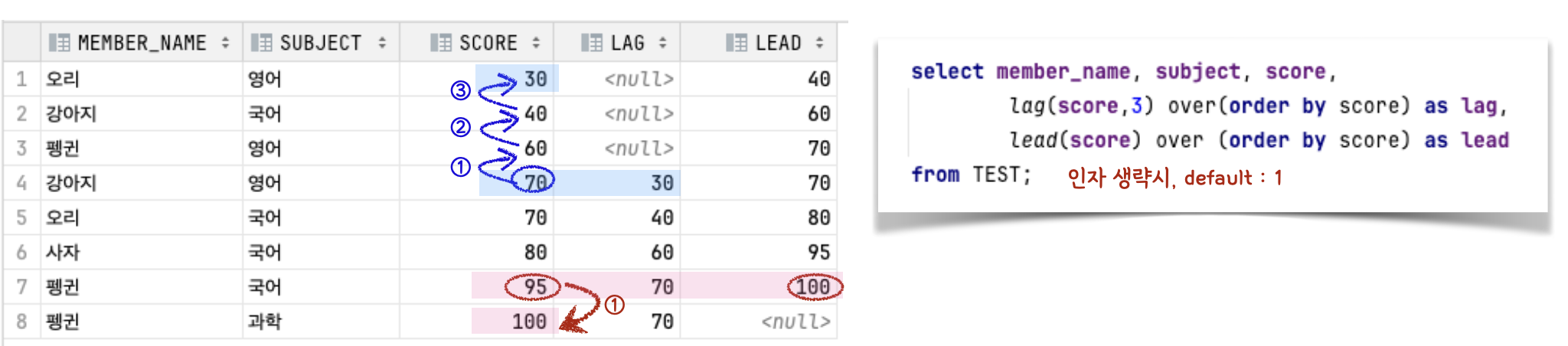
| LAG LEAD |
파티션별 특정 수만큼 앞에 / 뒤에 있는 데이터 구함두번째 인자값 생략시 default는 1 |
| 비율 함수 | ⚠️ MSSQL 지원 안함 |
|---|---|
| RATIO_TO_REPORT | 파티션별 합계에서 차지하는 비율RATION_TO_REPORT(score) OVER() = score ÷ sum(score) 한 값과 동일 |
| PERCENT_RANK | 해당 파티션의 맨 위 행을 0, 맨 아래행을 1로 놓고, 현재 행이 위치하는 백분위 순위 값PERCENT_RANK() OVER(order by score) → (rank -1) ÷ (count -1) 의미= ( RANK() OVER(order by score) -1 ) / (COUNT(*) OVER() -1) |
| CUME_DIST | 파티션에서의 누적 백분율 구함 ( 0 < 결과값 ≤ 1 )CUME_DIST() OVER( order by score )= COUNT() OVER(order by score) ÷ count() OVER() |
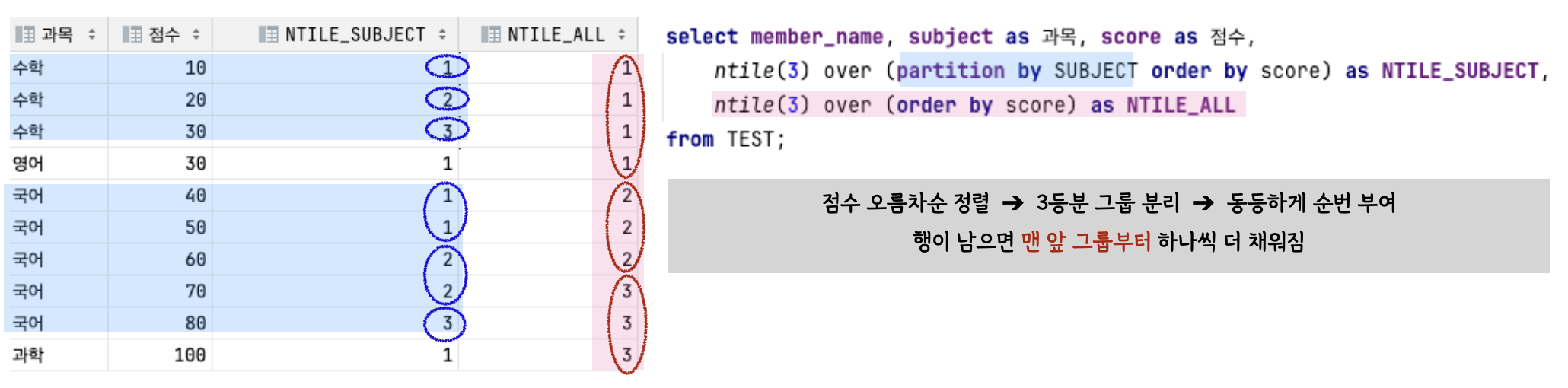
| NTILE | 주어진 수만큼 행들을 n등분한 후, 현재 행에 해당하는 등급 구하는 함수 똑같은 행 수로 할당되지 않은경우, 1그룹 부터 다시 할당됨 |
5. Top-N 쿼리
(1) ROWNUM
ROWNUM은 슈도컬럼(Pseudo Column) → 실제로 존재하지 않는 가짜 컬럼- 순번 필요한 상황에 활용 (자동 순번 매기기) → 1 부터 시작 + 무작위 랜덤으로 순번 매겨짐
- 주의 사항
- 진정한 Top-N 랭킹에 사용 불가 → order by 보다 where이 먼저 수행되기 때문
- ROWNUM 행이 반환될 때마다 순번이 1씩 증가하므로 건너뛰기 조건은 성립 불가 ⚠️
- ROWNUM은 항상
< 이나 <= 조건으로 사용해야 함
# SELECT 절에 ROWNUM 컬럼 추가해서 사용
SELECT ROWNUM, 제품명, 가격 FROM 제품;
# 사용 불가 : WHERE ROWNUM = 5 같은 조건 사용 불가
SELECT ROWNUM, 제품명, 가격 FROM 제품 where ROWNUM = 5;
# 무작위 5개를 뽑아낸 것
SELECT ROWNUM, 제품명, 가격 FROM 제품 where ROWNUM <= 5;
# ORDER BY절 보다 WHERE절이 먼저 수행됨
# 데이터를 랜덤으로 5개 뽑은 뒤에 ORDER BY 기준에 따라 순위를 매김
SELECT ROWNUM, 제품명, 가격 FROM 제품 WHERE ROWNUM <= 5 ORDER BY 가격;
(2) 진정한 TOP-N 쿼리 : 윈도우 함수의 순위 함수 활용
# ROW_NUMBER 활용
SELECT * FROM ( SELECT ROW_NUMBER() OVER(ORDER BY 가격) AS ROW_NUM, 제품명, 가격
FROM 제품) WHERE ROW_NUM <= 5;
# RANK 활용
SELECT * FROM ( SELECT RANK() OVER(ORDER BY 가격) AS RANK, 제품명, 가격
FROM 제품) WHERE RANK <= 5;
# DENSE_RANK 활용
SELECT * FROM ( SELECT DENSE_RANK() OVER(ORDER BY 가격) AS DR, 제품명, 가격
FROM 제품) WHERE DR <= 5;6. 셀프 조인 & 계층 쿼리
(1) 셀프 조인
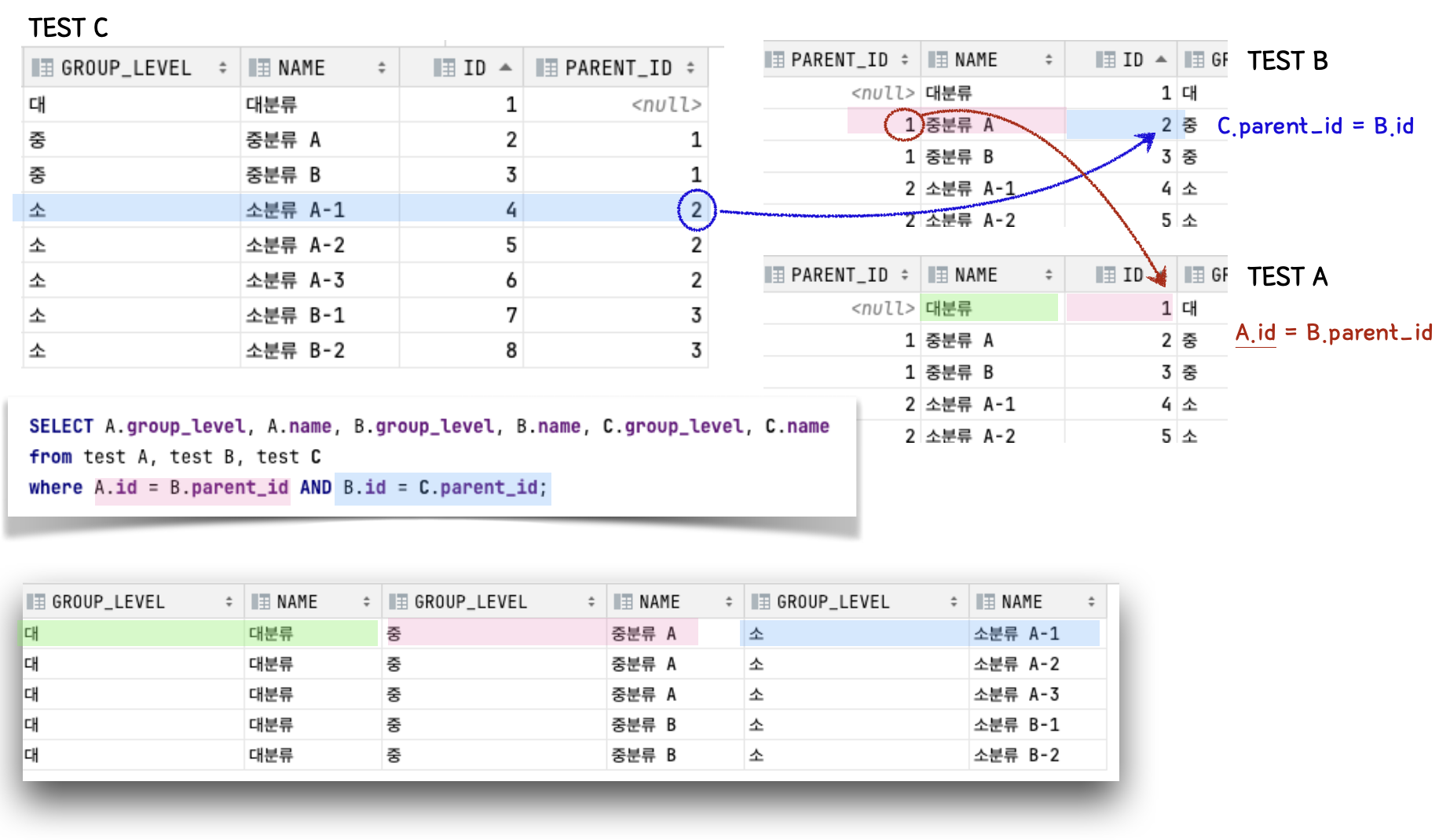
- 셀프 조인 : 나 자신과의 Join
- Depth가 깊어질 수록 Self Join이 반복됨 → 계층 쿼리 이용시 쿼리가 간략해짐
(2) 계층 쿼리
- 계층 쿼리 : 테이블에 계층 구조를 이루는 컬럼이 존재시 활용 가능
| 구문 | |
|---|---|
| LEVEL | 현재 DEPTH를 반환함 → Root 노드의 값은 1 |
SYS_CONNECT_BY_PATH (컬럼, 구분자) |
Root 노드부터 현재 노드까지의 경로를 출력해주는 함수 |
CONNECT_BY_ROOT 컬럼명 |
Root 노드의 컬럼값 반환 CONNECT_BY_ROOT name |
CONNECT_BY_ISLEAF |
가장 하위 노드인 경우 1을 반환, 그외에는 0을 반환 |
| START WITH | 경로가 시작되는 Root 노드를 생성해주는 절START WITH parent_id is null : parent_id가 null인 것 부터 |
| CONNECT BY | Root로 부터 자식 노드를 생성해주는 절 조건에 만족하는 데이터가 없을 때까지 노드 생성함 |
| PRIOR | 바로 앞에 있는 부모 노드의 값을 반환 |
order siblings by 컬럼명 |
같은 level 끼리 컬럼명으로 정렬 |
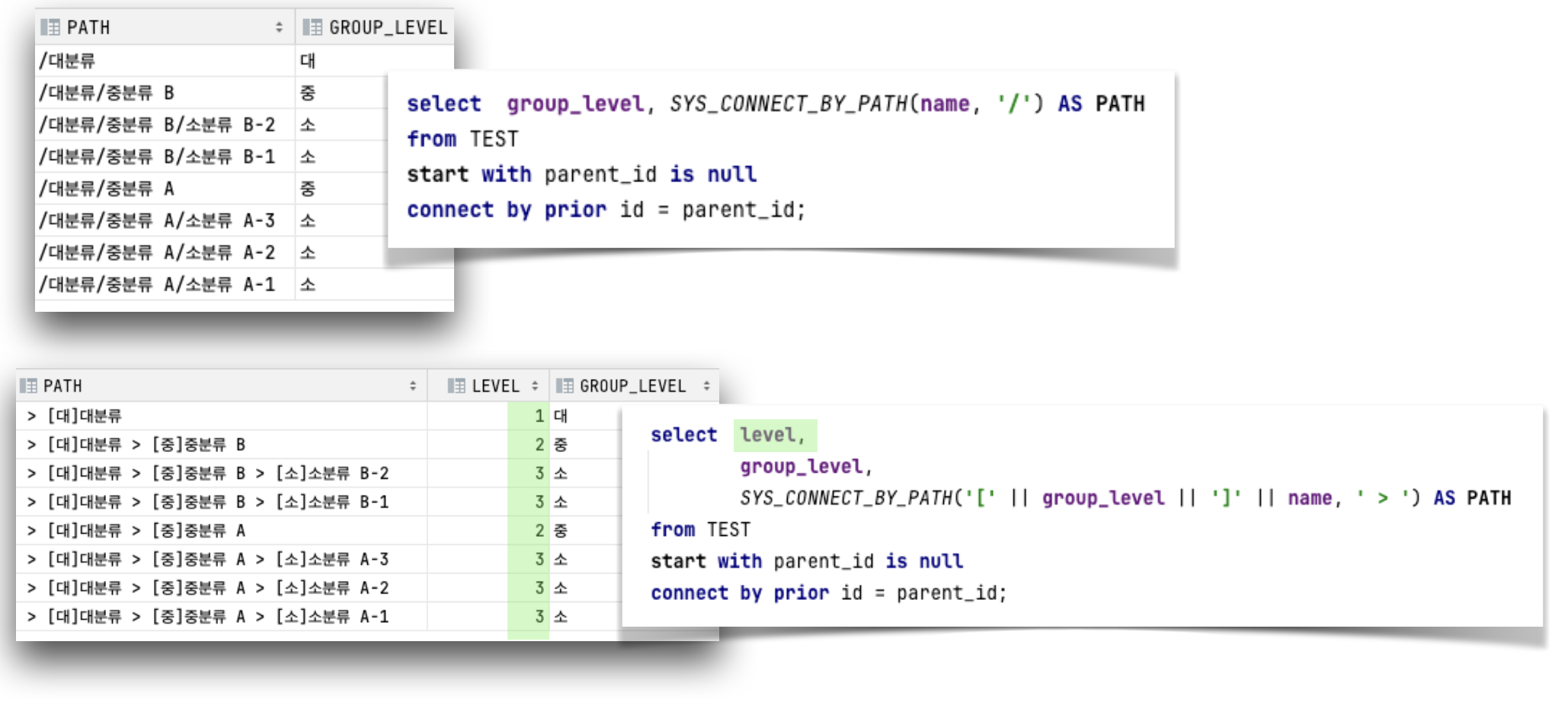
# 순방향 : root(상위) -> leaf(하위)
select level, group_level, SYS_CONNECT_BY_PATH( name, '>') AS PATH
from TEST
start with parent_id is null
connect by prior id = parent_id;
# 역방향 : leaf(하위) -> root(상위)
select level, group_level, SYS_CONNECT_BY_PATH( name, '>') AS PATH
from TEST
start with group_level = '소' # START WITH절을 하위노드로 설정
connect by id = prior parent_id # prior 설정 위치 변경
order siblings by name; # 같은 레벨 끼리 정렬되도록 함