SQLD 이론 요약 - part 2. SQL 기본
📗 Part 2. SQL 기본
1. 관계형 데이터베이스 개요
- 데이터베이스
- 데이터베이스(DB) : 데이터를 일정한 형태로 저장해 놓은 것
- DBMS : 효율적인 데이터 관리 및 데이터 손상시 필요한 데이터를 복구하기 위한 SW
- 관계형 데이터베이스 (RDB, RelationalDatabase)
- 관계형 데이터 모델에 기초를 둔 DB
- RDB 설계 = 모든 데이터를 2차원 테이블 형태로 표현한 뒤 각 테이블 간의 관계를 정의함
- RDBMS(Relational Database Management System)
- RDB를 관리 감동하기 위한 시스템이며, Oracle, MSSQL, MySQL 등이 이에 속함
- SQL (Structured Query Language) : RDB에서 데이터 정의, 조작, 제어를 위해 사용하는 언어
- DML : SELECT, INSERT, UPDATE, DELETE
- DDL : CREATE, ALTER, DROP, RENAME
- DCL : GRANT, REVOKE
- TCL : COMMIT, ROLLBACK
- 테이블 : RDB(관계형 데이터베이스)의 기본 단위, 데이터를 저장하는 객체
- 가로 = 행 = 로우(Row) = 튜플 = 인스턴스
- 세로 = 열 = 컬럼(Column) = 속성
2. SELECT 문
SELECT: 저장되어 있는 데이터 조회시 사용하는 명령어-
- (asterisk) 사용 → 전체 컬럼 조회됨 (조회되는 컬럼 순서는 테이블 컬럼 순서와 동일함)
- WHERE절 없으면 테이블 전체 Row가 조회됨
-
SELECT 컬럼1, 컬럼2 FROM 테이블 WHERE 컬럼1 = 'ABC';
SELECT * FROM 테이블;
SELECT 별칭1.컬럼1, 별칭1.컬럼2 FROM 테이블1 AS 별칭1;
SELECT 별칭1.컬럼1, 별칭1.컬럼2 FROM 테이블1 별칭1; #AS 생략 가능- Alias (별칭)
- Join 및 서브쿼리 사용시 컬럼명 앞에 테이블명을 명시하는 경우 테이블명을 짧게 줄여 사용 가능
- Alias 사용시 컬럼의 소유주를 명확히 인식 가능, 중복된 컬럼명 갖는 테이블 Join하여도 오류 발생안함
- AS라는 명령을 통해 별칭 지정가능 ( AS 생략도 가능 )
- 산술 연산자
| 우선순위 | 연산자 | 의미 | 연산자 | 의미 |
| 1 | ( ) | 괄호로 우선순위 조정 가능 | ||
| 2 | * | 곱하기 | / | 나누기 ( 0으로 나누면 에러 발생 ⚠️) |
| 3 | + , - | 더하기 , 빼기 | % (SQL Server) | 나머지 ( 0 으로 나눌경우 Null 반환 ) |
- 합성 연산자 : 문자와 문자 연결시 사용
SELECT '슈'||'비' AS NAME FROM DUAL;
SELECT COL1 || ' ' || 'NAME' || COL2 AS t from SAMPLE;
# t 결과 : 행복한 슈비슈밥 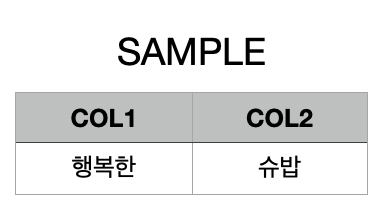
3. 함수
(1) 문자 함수
- ASCII 코드 : 128개의 문자를 숫자로 표현할 수 있도록 정의해놓은 코드
- LTRIM (
문자열[,특정문자]) , RTRIM (문자열[,특정문자])- 문자열의 L(왼쪽)/R(오른쪽)부터 지정한 특정문자 한글자씩 제거, 포함되지 않았으면 멈춤
- [] 는 옵션 → 특정 문자 미지정시 공백 제거
- TRIM (
[ {LEADING | TRAILING | BOTH} '특정문자' FROM ]문자열)- [] 는 옵션 → 옵션이 하나도 없을 경우 왼쪽과 오른쪽 공백 제거
- 위치 옵션 종류 : LEADING (앞), TRAILING(뒤), BOTH(앞,뒤)
- LTRIM과 RTRIM과 다르게 특정문자는 한글자만 지정 가능
- SUBSTR (
문자열,시작점[,길이])- 문자열 중 m위치에서 n개의 문자 반환 (m위치 계산시 1부터 시작)
- 길이 명시하지 않으면 문자열 끝까지 반환
- REPLACE (
문자열,찾을문자[,치환문자])- 특정 문자(문자열)을 치환할 때 사용
- 치환문자 생략하면 찾을문자가 제거됨
# CHR(ASCII코드) = SQLServer(MSSQL)의 경우 CHAR(ASCII 코드)
CHR(65) # 결과 : A (ASCII 값에 해당하는 문자 반환)
LOWER('APPLE') # 결과 : apple (문자열을 소문자로)
UPPER('aws') # 결과 : AWS (문자열을 대문자로)
LTRIM('AA ABCD', 'A') # 결과 : ' ABCD' (왼쪽에서 A 제거, AA뒤 공백에서 멈춤 -> 공백 유지됨)
LTRIM('ABCCBAHJ', 'ABC') # 결과 : HJ ('ABC'를 제거하는 것이 아닌 'A','B','C'를 삭제)
TRIM(' tiger ') # 결과 : 'tiger'
TRIM('#$' from '$#$tiger###') # 결과 : 'tiger'
TRIM(LEADING '#' from '##ABC##') # 결과 : ABC##
TRIM(TRAILING '#' from '##ABC##') # 결과 : ##ABC
TRIM(LEADING '#' from '##ABC##') # 결과 : ABC
SELECT LENGTH('가나다라마') FROM DUAL : # 결과 5 (문자열 길이 반환)
SELECT SUBSTR ('가나다라마',1,3) FROM DUAL; # 결과 : 가나다 (가를 1로 생각)
SELECT SUBSTR ('가나다라마',3,1) FROM DUAL; # 결과 : 다
SUBSTR ('가나다라마', -3) # 결과 : 다라마 (마를 -1로 생각, -3부터 끝까지)
REPLACE('Elizabeeth', 'e' , '*') # 결과: Elizab**th (오라클은 대소구분함)
REPLACE(REPLACE('가나다가나라' , '라', '#') ,'가', '?') # 결과: '?나다?나#'
# REPLACE ('02-999-888' , '-' , ' ')와 결과 동일
REPLACE('02-999-888' , '-') # 결과: 02999888
LPAD('가나다', 5, '#') # 결과: ##가나다 (설정한 길이가 될 때까지 왼쪽을 특정문자로 채움)
(2) 숫자 함수
| 숫자 함수 | 의미 | 예시 |
|---|---|---|
| ABS(수) | 절댓값 반환 | ABS(-5) → 5, ABS(2) → 2 |
| SIGN(수) | 부호 반환 (양수 : 1, 음수 : -1, 0 : 0) |
SIGN(-7) → -1, SIGN(7) → 1SIGN(0) → 0 |
| ROUND( 수 [,자릿수] ) | 지정된 소수점 자릿수까지 반올림 자릿수가 음수이면 지정된 정수부를 반올림 |
ROUND(123.45, 1) → 123.5ROUND(123.45, -2) → 100 |
| TRUNC( 수 [,자릿수] ) | ROUND (반올림) ↔ TRUNC (버림) | TRUNC(987.654, 1) → 987.6 |
| CEIL(수) ↔ Floor(수) | CEIL : 소수점 이하의 수 올림 FLOOR : 소수점 이하의 수 버림 |
CEIL(3.86) → 4 CEIL(-50.8) → -50FLOOR(3.86) → 3 FLOOR(-50.8) → -51 |
| MOD( A , B ) | A ÷ B의 나머지 반환 B가 0일 경우 A를 반환함 A, B 모두 음수이면, 나머지도 음수 반환 |
MOD (15, 7) → 1 MOD(15, -7) → 1MOD(-8, 0) → -8MOD (-15, -7) → -1 |
(3) 날짜 함수
| SYSDATE | 현재의 연, 월, 일, 시, 분, 초 반환 SELECT SYSDATE FROM DUAL; |
EXTRACT ( {특정단위} FROM 날짜 ) |
특정 단위 종류 : YEAR, MONTH, DAY, HOUR, MINUTE, SECOND 날짜에서 특정 단위만 출력 |
EXTRACT(MONTH FROM SYSDATE) → 8 (현재 달만 출력) |
|
ADD_MONTHS(날짜 , 특정 개월수 ) |
날짜에 특정 개월 수 더한 날짜 반환 계산한 일자가 없으면 → 해당 월의 마지막 일자가 반환됨 (오류 발생X) |
ADD_MONTHS(TO_DATE('12-31','MM-DD'),-1) 2024-11-30 00:00:00ADD_MONTHS(TO_DATE('2024-01-31'), 1) 2024-02-29 00:00:00 |
(4) 변환 함수
- 암시적 형변환 : DB가 내부적으로 알아서 데이터 유형을 변환함
select * from where birthday = 20240801- VARCHAR 유형 의 birthday 컬럼을 숫자와 비교 → 오류 발생하지 않음
- DB 내부적으로 birthday 컬럼을 NUMBER형으로 암시적 형변환 진행함
- 명시적 형변환 : 변환 함수 사용하여 데이터 유형 변환을 명시적 나타냄
| 명시적 형변환 함수 | 예시 |
|---|---|
| TO_NUMBER (문자열) 문자 → 숫자로 형변환 |
TO_NUMBER(’99’) → 99TO_NUMBER(’AB’) → ⚠️ 에러 발생 |
TO_CHAR( 숫자 or 날짜 [, 포맷] )숫자 or 날짜 → 문자로 형변환 |
TO_CHAR(99) → ‘99’TO_CHAR(SYSDATE, ‘YYYYMMDD HH24MISS’)→ 20240801 213057 |
TO_DATE( 문자열, 포맷 )포맷형식의 문자형 → 데이터 날짜로 형변환 |
TO_DATE(’20240801’ , ‘YYYYMMDD’) → 2024-08-01YYYY(년) MM(월) DD(일) HH : 시(12) HH24 : 시(24) MI : 분 SS : 초 |
(5) NULL 관련 함수
NVL(A, B) |
A의 값 null이 아니면 A 반환 null일 경우 B를 반환 |
NVL(review_score, 0)→ review_score가 null이면 0 반환 |
NVL2(A,B,C) |
A가 null이 아니면 B를 반환 null인 경우 C를 반환 |
NVL2(review_score, ‘리뷰있음’, ‘리뷰없음’)→ reviw_score 값이 null이면 리뷰 없음 |
NULLIF(A, B) |
A와 B가 같으면 null 반환, 같지 않으면 A반환 |
NULLIF(review_score, 0)→ review_score가 0과 같으면 null 반환 |
COALESCE(A,B,C ∙∙) |
null이 아닌 최초의 인수를 반환 | COALESCE(phone, email, fax) AS contact→ 3가지 값 중 존재하는 첫번째 값 반환 |
(6) CASE
- CASE는 함수보다 구문에 가까움 →
~이면 ~이고, ~이면 ~이다식으로 표현되는 구문 - ELSE 뒤의 값이 default 값이 됨 → else 생략시, default 값은 null로 설정됨
SELECT subway_line
CASE WHEN subway_line = '1' THEN 'blue'
WHEN subway_line = '2' THEN 'green'
ELSE 'gray' #생략가능
END AS line_color
FROM subway_info
# 동일한 표현법
CASE subway_line
WHEN '1' THEN 'blue'
WHEN '2' THEN 'green'
[ ELSE 'gray' ]
END
# 오라클에는 동일한 기능을 하는DECODE 함수가 있음
DECODE(subway_line, '1','blue', '2','green' [,'gray'])4. WHERE 절
(1) where 절
- insert를 제외한 DML 수행시 원하는 데이터만 골라 수행할 수 있도록 해주는 구문
- where 절 위치
select * from student where name = '슈비';
update student set city = '서울' where name = '슈비';
delete from student where name = '슈비'; where name = 슈비→ ⚠️ 에러 발생 (‘슈비’와 같이 인용부호로 감싸야 함 )
(2) where절 연산자
-
논리 연산자 : SQL에 명시된 순서와 상관없이
( ) → NOT → AND → OR 순으로 처리됨 !! -
조건식에서 컬럼명은 보통 좌측에 위치하지만 우측에 위치해도 정상 동작함
-
연산자 우선순위
산술 → 연결 → 비교 → SQL 연산자 → 논리 연산자 *,/+,-||=,<,><=,>=IN,LIKE,BETWEEN,IS NULLNOT→AND→OR
| 논리 연산자 | 의미 | 예시 |
|---|---|---|
NOT |
TRUE이면 FALSE이고, FALSE이면 TRUE | where not id > 10 |
AND |
모든 조건이 TRUE | where id > 10 and id < 20 |
OR |
하나 이상의 조건이 TRUE여야 함 | where id = 10 or id = 20 |
| 비교 연산자 | 의미 | 예시 |
|---|---|---|
= , < , <= , > , >= |
같음, 작음, 작거나 같음, 큼, 크거나 같음 | where age = 10 |
| 부정 비교 연산자 | 의미 | 예시 |
|---|---|---|
!= , ^= , <> , not 컬럼명 = |
같지 않음 | where isActive <> ‘Y’→ isActive가 ‘N’인 것만 조회됨 |
not 컬럼명 > |
크지 않음 | where no age > 18 |
| SQL 연산자 | 의미 | 예시 |
|---|---|---|
BETEWEEN A AND B |
A와 B의 사이인 행 (A, B 포함) |
where age between 10 and 20; → 10 ≤ age ≤ 20 조회 |
NOT BETWEEN A AND B |
A와 B 사이가 아닌 행 (A, B 미포함) |
where id not between 3 and 8; = where not (id between 3 and 8); = where not ( id >= 3 and id <= 8 ); = where id < 3 or id > 8; |
LIKE '비교 문자열' |
비교 문자열 포함하는 행% : 문자열_ : 하나의 문자 _ , % 기호를 검색하려면ESCAPE 지정해야 함 |
where name like ‘%학교’ → 학교로 끝나는 행 where name like ‘김%’ → 김으로 시작하는 행where title like ‘%#%%' escape '#' → #% 자체가 %로 인식, 제목에 % 들어가는 행where title like ‘%@_%' escape '@' → @_ 자체가 _ 로 인식, 제목에 _가 들어가면 행where name like ‘_슈비_’ → 4글자where name like ‘_ _슈비’ → 4글자where name like ‘_슈비’ → 3글자 |
IN (리스트) |
List 중 하나라도 일치하는 행 | where grade in (’A’,‘B’) → 등급이 A이거나 B인 행 |
NOT IN (리스트) |
List 중 일치하는 것 없는 행 | where grade not in (’A’,‘B’)where not ( grade in (’A’,‘B’)) where not ( grade = ’A’ or grade = ‘B’)where ( grade <> ’A’ and grade <> ‘B’) |
IS NULL |
null 값인 행 | where phone is null → null인 행 조회 |
IS NOT NULL |
null 값이 아닌 행 | where phone is not null |
5. GROUP BY, HAVING 절, ORDER BY 절
💡 SELECT 문의 논리적 수행 순서
SELECT→ (5)
FROM→ ①
WHERE→②
GROUP BY→③
HAVING→ (4)
ORDER BY→ (6)
SELECT product_code, product_name, COUNT(order_cnt) AS order_cnt
FROM order_product
WHERE order_date BETWEEN '20240801' AND '20240831'
GROUP BY product_code
HAVING COUNT(order_cnt) >= 1000;
ORDER BY product_name DESC, created_at-
GROUP BY 컬럼명: 해당 컬럼 기준으로 그룹핑 -
집계 함수: 집계 함수 활용하면 그룹별 집계 데이터 도출 가능집계 함수 기능 COUNT(*)전체 Row를 count하여 반환 (✅ null 포함) COUNT(컬럼명)컬럼값이 null인 Row 제외하고 count 반환 COUNT (DISTINCT컬럼명 )컬럼값이 null인 Row 제외하고 중복 제거한 count 반환 SUM(컬럼명),AVG(컬럼명)컬럼값들의 합계 / 평균 반환 (null인 Row 제외) MIN(컬럼명),MAX(컬럼명)컬럼값들의 최솟값 / 최댓값 반환 (null인 Row 제외) -
HAVING- 집계함수에 대한 조건절 = GROUP BY절 이후에 수행됨 = 그룹핑을 한 후에 특정 그룹 골라낼 수 있음
HAVING은SELECT이전에 수행됨SELECT절에 명시되지 않은 집계함수로도 조건 부여 가능HAVING절에서는SELECT 절에서 alias 준 것과 상관 없음 !!
- 주의사항
WHERE을 사용해도 되는 조건도HAVING을 사용하면 성능이 떨어짐- 비용이 많이 드는
GROUP BY수행 전에 최대한WHERE로 필터링이 선행되는 것이 좋음
-
ORDER BY: 데이터 정렬시 사용- SELECT문에서 논리적으로 가장 마지막에 수행됨 = select 에서 정의한 alias 사용 가능
ORDER BY생략시 임의의 순서대로 출력됨- 오라클은 NULL을 최댓값으로 취급 (SQL Server는 반대)
ORDERY BY옵션DESC(내림차순),ASC(오름차순)→ 옵션 생략시 ASC 기본값- NULL 순서 변경 →
ORDER BY절에NULLS FIRST,NULLS LAST옵션 가능
6. JOIN
EQUI JOIN: Equal(=) 조건으로 JoinNON EQUI JOIN: Equal(=) 조건 이외에 다른 조건(BETEWEEN, >, < 등)으로 Join- Join되는 2개의 테이블에 모두 존재하는 컬럼의 경우, 컬럼명 앞에 반드시 테이블명이나 Alias 명시 필수
OUTER JOIN: 조건에 만족하지 않는 행들도 출력되는 형태LEFT OUTER JOIN: Join 성공한 데이터 + Join 성공하지 못한 Left Table 데이터가 함께 출력됨- 오라클에서는 모든 행이 출력되는 테이블의 반대편 테이블의 옆에 (+)를 붙여서 작성
# EQUI JOIN 예시: 상품코드 기준으로 Product 테이블과 Review 테이블 조인
SELECT P.product_code, P.product_name, R.review_content, R.writer_id
FROM product P, review R
WHERE P.product_code = R.product_code;
# NON EQUI JOIN 예시: 이벤트 기간에 리뷰 작성한 경우 조회 (Review 테이블과 Event 테이블 조인)
SELECT E.event_name, E.start_date, E.end_date, R.writer_id, R.created_at
FROM event E, review R
WHERE R.created_at BETWEEN E.start_date AND E.end_date;
# 3개 테이블 Join
SELECT P.product_name, E.event_name, R.writer_id
FROM product P, event E, review R
WHERE P.product_code = R.product_code
AND R.created_at BETWEEN E.start_date AND E.end_date;
# LEFT OUTER JOIN (오라클에서는 + 기호 사용 가능)
SELECT P.product_name, R.review_content
FROM product P, review R
WHERE p.product_code = R.product_code(+);7. STANDARD JOIN
- Standard Join 등장 ( =
ANSI JOIN,표준 조인)- RDBMS를 벤더별 구분 하면, Oracle, SQL Server(MS SQL), MySQL, MariaDB 등 있음
- 벤더마다 SQL 문법 차이가 크면 호환성 이슈 발생 → 표준이 되는 ANSI SQL 지정 함
STANDARD JOIN은 ANSI SQL 중 하나로, 어떤 벤더에서도 실행되는 Join 쿼리ON 절사용 → ON 절에 정의된 조건으로 JOIN의 여부를 판단하게 됨
- Standard Join 종류
INNER JOIN: Join 조건에 충족하는 데이터만 출력OUTER JOIN: 기준이 되는 테이블의 데이터는 Join 조건에 충족하지 않아도 출력됨LEFT OUTER JOIN,RIGTH OUTER JOINFULL OUTER JOIN: 왼쪽, 오른쪽 테이블의 데이터가 모두 출력됨 (단, 중복값은 제거됨)
NATURAL JOIN: 두 테이블 간 동일한 이름을 가진 모든 공통 속성 기준으로 자동 결합하는 JoinCROSS JOIN: Join 조건 없는경우, 모든 가능 조합 생성 (=Cartesian Product,카티션 곱)

- NATURAL JOIN 추가 설명
- ⚠️ SQL Server(MSSQL)에서 지원하지 않음
- ON 절 사용 불가
- 예시) 두 테이블에서 이름이 동일한 속성은 ID, NAME, CODE → 3가지 속성값이 동일한 경우만 Join
- 오라클 → USING 조건절을 이용해 두 테이블의 동일 컬럼명 중에서 원하는 컬럼만 선택도 가능
- ⚠️ USING절에 정의한 컬럼은 alias나 테이블명을 select절에서 사용 못함